Machine learning в индустрии моды. Определяем бренд по изображению
С тех пор, как 10 лет назад IBM’s Deep blue победил чемпиона мира по шахматам Каспарова, а примерно 2 года назад AlphaGo от Google одержал победу со счетом 4-1 в игре с гроссмейстером, AI достиг огромного прогресса в своем развитии. Еще несколько лет назад, люди думали, что ИИ – это не более, чем шахматные игры. Однако сегодня Machine learning глубоко проникает в нашу повседневную жизнь: от выявления рака по рентгеновским снимкам, помощи в финансовой сфере до всем известного Face detection в iPhone. AI уже очень широко используется среди нас.
Компьютерное зрение – уже сложившаяся и устоявшаяся область. Машинное обучение с легкостью может распознавать лица людей, кошек, собак. Но способно ли ML обладать чувством искусства, как настоящий дизайнер? Если загрузить изображению с определенной вещью или эмблемой, то сможет ли компьютер определить, к какому бренду это принадлежит?
Возьмем 3 известных бренда для теста
1. Balenciaga

2. Burberry

3. Nike

Скорее всего, Nike и Burberry легко определить, поскольку их вещи имеют определенные повторяющиеся паттерны. Что касается Balenciaga, то тут сказать сложнее.
Загрузим выборку данных из Google
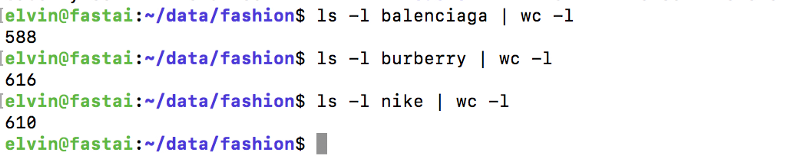
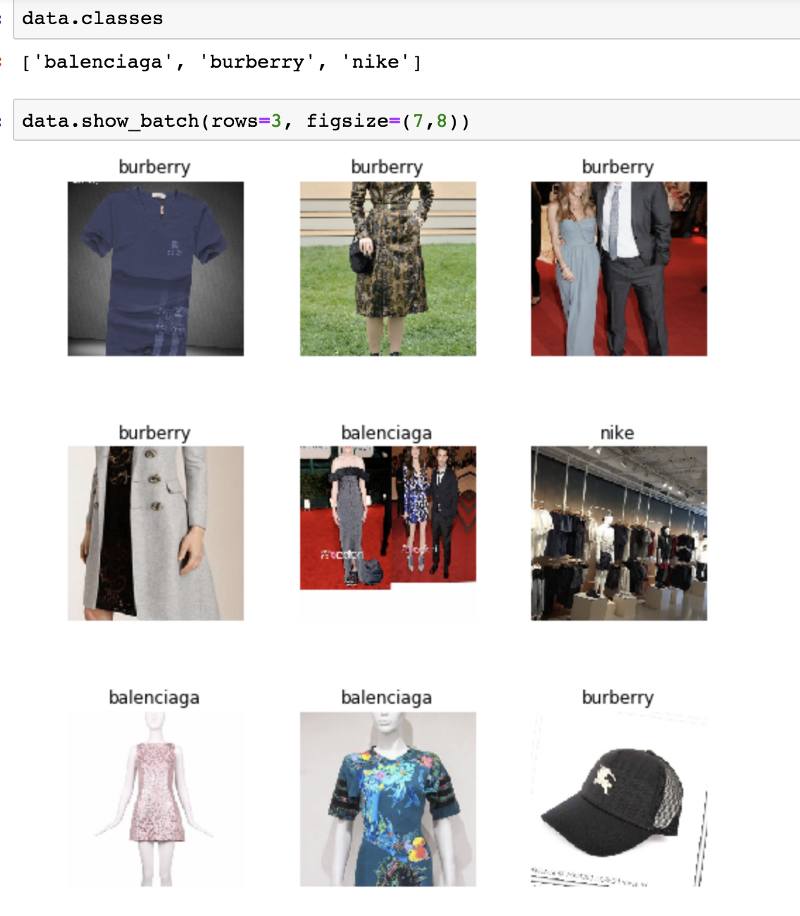
Около 600 изображений для каждого бренда
Подача данных в модель
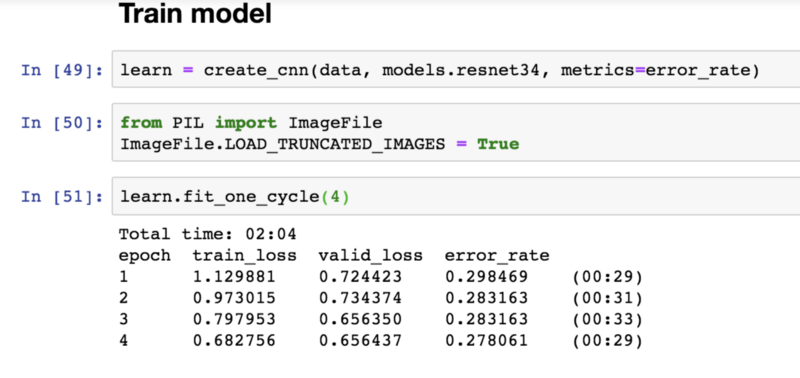
Обучение модели
Процент ошибок равен примерно 0,278%. Это довольно неплохой показатель, т.к. означает, что около ¾ результатов, которые выдает компьютер, - верные.
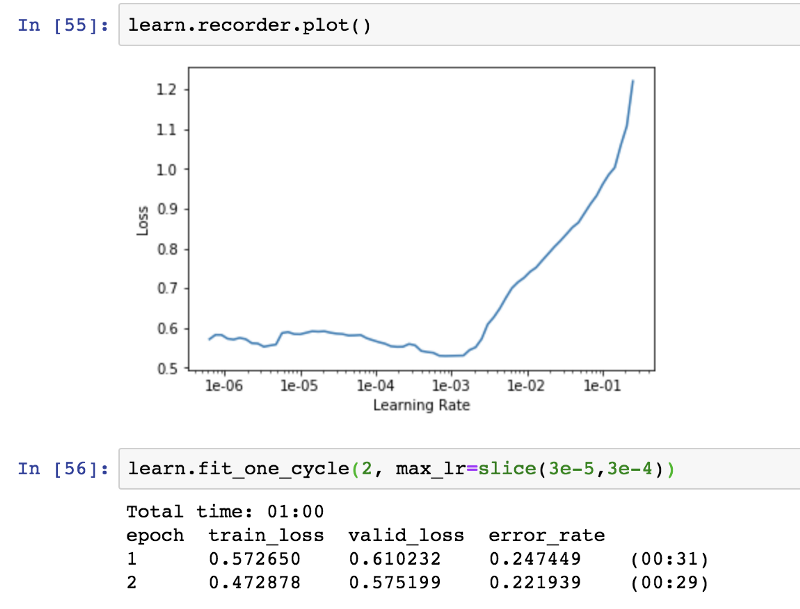
Корректировка настроек модели
Процент ошибок значительно уменьшается за счет разморозки модели и подготовки всех уровней скорректированными показателями обучения.
Результат
Процент ошибок падает до 0,22%. Это очень хороший результат, поскольку изображения содержат в себе не только информацию об одежде, но и об эмблеме, обуви, модели, одетой в целый комплект одежды данного бренда, а иногда и нескольких моделей, стоящий вместе на одном изображении.
Существует множество возможностей для уменьшения показателя ошибок модели, таких как:
1. Убрать лишнее: удалить не связанные между собой изображения.
2. Сократить дисперсию: классифицировать по категориям (обувь, одежда и т.д.) перед обучением.
3. Подготовить больше данных. 600 изображений, возможно, - это очень мало, учитывая, что мы сравниваем все продукты (одежду, обувь, сумки, логотипы – все это).
Интерпретация результата
Изучая confusion matrix, мы можем отметить, что бренд Balenciaga имеет больше схожих черт с Burberry, нежели с Nike. Это может означать, что потенциальным конкурентом Balenciaga на рынке скорее всего является Burberry, а не Nike.

Анализируя результат, мы можем получить много информации сравнивая продукцию разных брендов или продукцию внутри одного бренда. Например:
1. Какие бренды являются потенциальными конкурентами?
2. Совместимы ли новые сезонные продукты с основным стилем бренда?
3. Насколько дизайнерские вещи вливаются в бренд и в то же время привносят что-то новое? Изучая данные, компьютер может дать оценку.
4. Как стили бренда соотносятся с различными человеческими чувствами/эмоциями?
5. Какое впечатление вызывает у покупателя новая линейка товаров?
На все вышеперечисленные вопросы поможет ответить Machine learning.
Давайте добавим топ-10 брендов для тестирования
1. https://www.businessinsider.com/hottest-fashion-brands-in-the-world-2018-7#7-versace-4
Бренды:
classes = [‘balenciaga’, ‘burberry’, ‘dolce_n_gabbana’, ‘fendi’, ‘givenchy’, ‘gucci’, ‘nike’, ‘off-white’, ‘prada’, ‘versace’, ‘vetements’]
Подготовка данных
Загрузите около 600 изображений для каждого бренда
Обучение модели
Процент ошибок вырос до 0,568%. Это неудивительно, поскольку мы добавили на 300% больше брендов, а 600 изображений просто недостаточно для обучения.
Можете ли вы сказать, какому бренду принадлежит эта вещь, не смотря на лейбл?

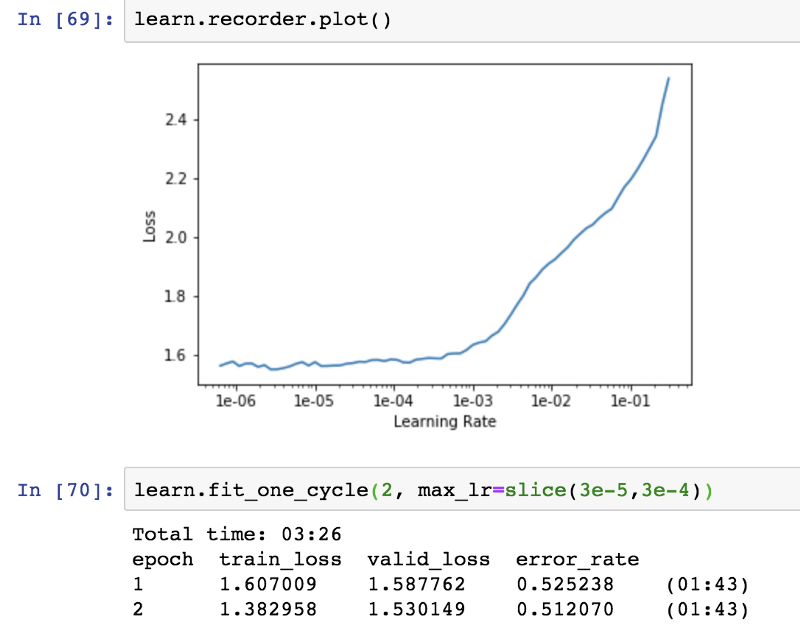
Корректировка настроек модели
Процент ошибок значительно падает за счет корректировки скорости обучения и повторного обучения на всех уровнях.
Интерпретация
Изучая данные, мы можем предположить, что Gucci и Dolce and Gabbana являются наиболее потенциальными конкурентами друг друга. Хотя Givenchy и Versace менее склонны конкурировать напрямую.
Вся эта информация помогает принимать очень важные решения для самих брендов.

Заключение
Несомненно, что, просто глядя на несколько брендов и такой небольшой набор данных, мы уже можем извлечь столь ценную информацию. Поэтому целесообразно полагать, что индустрия моды в скором времени начнет внедрять Machine learning в свои процессы.






