Прогнозирование текучести кадров с помощью Python
В этой статье вы узнаете, как можно проанализировать текучесть кадров с помощью библиотеки Python’s Scikit-Learn. Мы познакомим вас с Logistic Regression, Random Forest, и Support Vector Machine. Мы также рассмотрим точность моделей, построенных с помощью Machine Learning, и оценим направления дальнейшего развития. И все это мы сделаем в Python. Давайте начнем!
Исходный код ipython notebook и данные
Предварительная обработка данных
Данные были загружены из Kaggle . Все достаточно просто. Каждая строка представляет сотрудника, каждый столбец содержит характеристики:
- satisfaction_level (0-1)
- last_evaluation (время, прошедшее с момента последней оценки в годах)
- number_projects (количество выполненных проектов
- average_monthly_hours (среднее количество рабочих часов за месяц)
- time_spend_company (время работы в компании в годах)
- work_accident (у сотрудника был несчастный случай на рабочем месте)
- left (работник уволился (1 или 0))
- promotion_last_5years (было ли у сотрудника повышение за последние 5 лет)
- sales (отдел, в котором работает сотрудник)
- salary (уровень заработной платы)
import pandas as pd
hr = pd.read_csv('HR.csv')
col_names = hr.columns.tolist()
print("Column names:")
print(col_names)
print("\nSample data:")
hr.head()
Названия столбцов:
['satisfaction_level', 'last_evaluation', 'number_project', 'average_montly_hours', 'time_spend_company', 'Work_accident', 'left', 'promotion_last_5years', 'sales', 'pay']
Пример данных:

Переименуем столбец «sales» в «department».
hr=hr.rename(columns = {'sales':'department'}) Тип столбцов можно узнать следующим образом:
hr.dtypes

Наши данные полные, без пропущенных значений
hr.isnull().any()
Данные содержат 14999 сотрудников и 10 характеристик.
hr.shape
(14999, 10)
Столбец «left» - это переменная с результатами 1 и 0. 1 - для сотрудников, покинувших компанию, и 0 - для тех, кто этого не сделал.
Раздел «department» имеет много категорий, поэтому нам необходимо сократить их количество для лучшего моделирования. Колонка «department» включает следующие категории:
hr['department'].unique()
array([‘sales’, ‘accounting’, ‘hr’, ‘technical’, ‘support’, ‘management’,
‘IT’, ‘product_mng’, ‘marketing’, ‘RandD’], dtype=object)
Давайте объединим “technical”, “support” and “IT” вместе и назовем их “technical”.
import numpy as np
hr['department']=np.where(hr['department'] =='support', 'technical', hr['department'])
hr['department']=np.where(hr['department'] =='IT', 'technical', hr['department'])
После изменения это выглядит так:
[‘sales’ ‘accounting’ ‘hr’ ‘technical’ ‘management’ ‘product_mng’
‘marketing’ ‘RandD’]
Изучение данных
Прежде всего, давайте выясним количество сотрудников, покинувших компанию, и тех, кто этого не сделал:
hr['left'].value_counts()
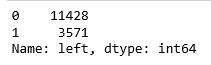
Согласно нашим данным, 3571 сотрудник ушел, а остались – 11428 работников.
Давайте получим представление чисел в этих двух классах:
hr.groupby('left').mean() 
Несколько наблюдений:
- Средний уровень удовлетворенности тех сотрудников, кто работает в компании, выше, чем тот же показатель у уволившихся работников.
- Среднемесячные рабочие часы сотрудников, покинувших компанию, больше, чем у оставшихся сотрудников.
- Сотрудники, у которых были несчастные случаи на рабочем месте, с меньшей вероятностью уходят, чем сотрудники, у которых не было несчастных случаев на производстве.
- Сотрудники, которые были повышены за последние пять лет, с меньшей вероятностью уходят, чем те, кто не получил повышение в последние пять лет.
Мы можем рассчитать значения для категориальных переменных, таких как «department» и «salary», чтобы получить более подробное представление о наших данных следующим образом:
hr.groupby('department').mean() 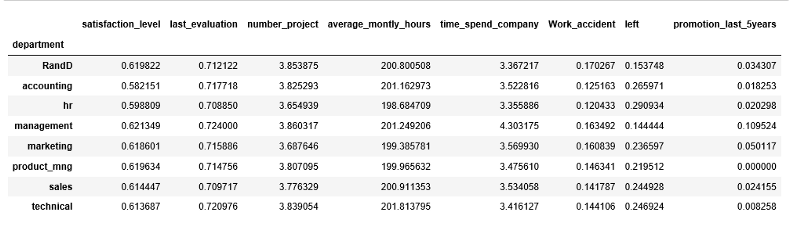
hr.groupby('salary').mean() 
Визуализация данных
Теперь давайте визуализируем наши данные, чтобы получить более четкую картинку.
График текучести кадров по отделам
%matplotlib inline
import matplotlib.pyplot as plt
pd.crosstab(hr.department,hr.left).plot(kind='bar')
plt.title('Turnover Frequency for Department')
plt.xlabel('Department')
plt.ylabel('Frequency of Turnover')
plt.savefig('department_bar_chart')
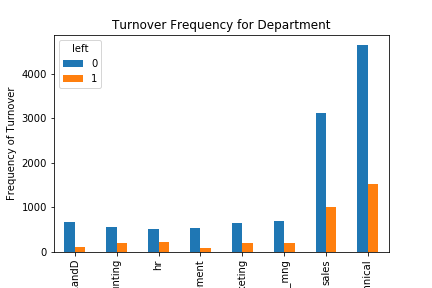
Очевидно, что частота сменяемости сотрудников во многом зависит от того, в каком отделе они работают. Таким образом, отдел может быть хорошим предиктором переменной результата.
График сменяемости кадров в зависимости от среднего уровня заработной платы
table=pd.crosstab(hr.salary, hr.left)
table.div(table.sum(1).astype(float), axis=0).plot(kind='bar', stacked=True)
plt.title('Stacked Bar Chart of Salary Level vs Turnover')
plt.xlabel('Salary Level')
plt.ylabel('Proportion of Employees')
plt.savefig('salary_bar_chart')
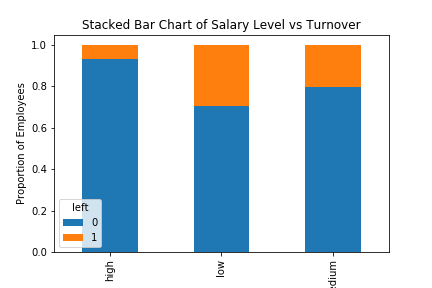
Доля сменяемости сотрудников во многом зависит от уровня их заработной платы; следовательно, уровень зарплаты может быть также хорошим предиктором в прогнозировании результата.
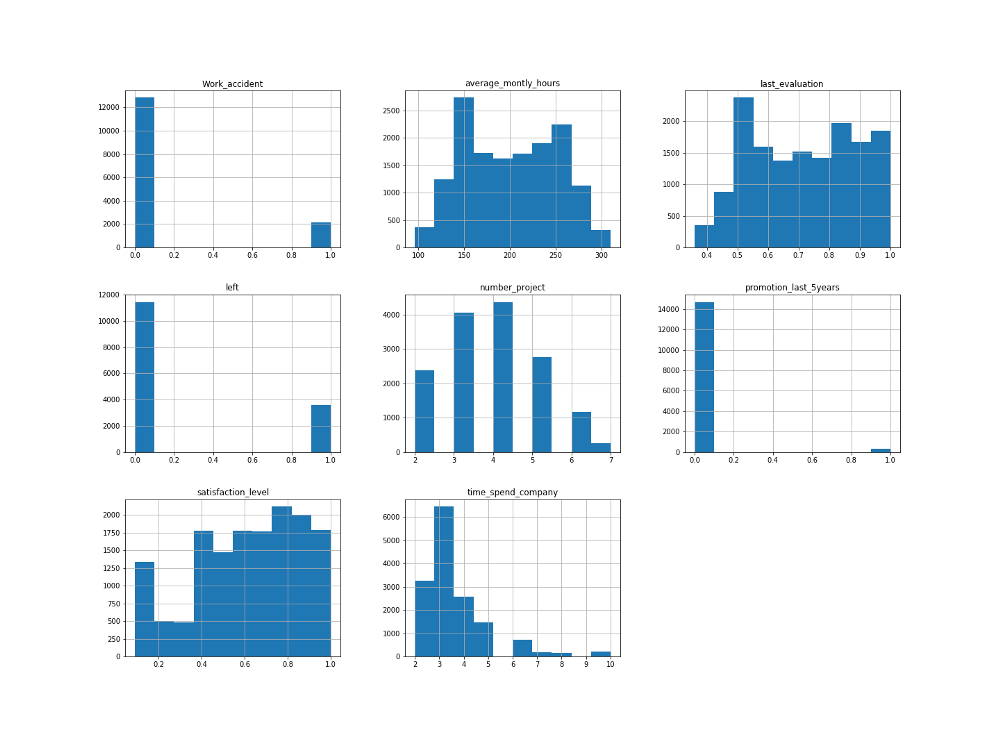
Гистограммы часто являются одним из наиболее полезных инструментов, которые мы можем использовать для числовых переменных.
Гистограмма числовых переменных
num_bins = 10
hr.hist(bins=num_bins, figsize=(20,15))
plt.savefig("hr_histogram_plots")
plt.show()
Создание фиктивных переменных для категориальных показателей
В наборе данных есть две категориальные переменные (отдел, зарплата), и они должны быть преобразованы в фиктивные переменные, прежде чем их можно будет использовать для моделирования.
cat_vars=['department','salary']
for var in cat_vars:
cat_list='var'+'_'+var
cat_list = pd.get_dummies(hr[var], prefix=var)
hr1=hr.join(cat_list)
hr=hr1
Фактическая категориальная переменная должна быть удалена после создания фиктивных переменных.
Имена столбцов после создания фиктивных переменных для категориальных переменных:
hr.drop(hr.columns[[8, 9]], axis=1, inplace=True)
hr.columns.values
array([‘satisfaction_level’, ‘last_evaluation’, ‘number_project’,
‘average_montly_hours’, ‘time_spend_company’, ‘Work_accident’,
‘left’, ‘promotion_last_5years’, ‘department_RandD’,
‘department_accounting’, ‘department_hr’, ‘department_management’,
‘department_marketing’, ‘department_product_mng’,
‘department_sales’, ‘department_technical’, ‘salary_high’,
‘salary_low’, ‘salary_medium’], dtype=object)
“left” является конечной переменной, а все остальные – предикторы для прогнозирования.
hr_vars=hr.columns.values.tolist()
y=['left']
X=[i for i in hr_vars if i not in y]
Отбор признаков
Recursive Feature Elimination (RFE) работает через рекурсивное удаление переменных и построение модели на тех переменных, которые остаются. RFE использует точность модели для определения того, какие переменные (и комбинация переменных) способствуют в наибольшей степени прогнозированию целевого показателя.
Давайте используем отбор признаков, чтобы помочь решить, какие переменные являются наиболее значимыми для прогнозирования текучести кадров с максимальной точностью. Всего у нас 18 столбцов, как насчет отобрать из них 10?
from sklearn.feature_selection import RFE
from sklearn.linear_model import LogisticRegression
model = LogisticRegression()
rfe = RFE(model, 10)
rfe = rfe.fit(hr[X], hr[y])
print(rfe.support_)
print(rfe.ranking_)
[True True False False True True True True False True True False
False False False True True False]
[1 1 3 9 1 1 1 1 5 1 1 6 8 7 4 1 1 2]
Вы можете видеть, что RFE выбрала для нас 10 переменных, которые помечены True в support_ array, и знаком «1» в ranking_array. Вот что получилось:
[‘satisfaction_level’, ‘last_evaluation’, ‘time_spend_company’, ‘Work_accident’, ‘promotion_last_5years’, ‘department_RandD’, ‘department_hr’, ‘department_management’, ‘salary_high’, ‘salary_low’]
cols=['satisfaction_level', 'last_evaluation', 'time_spend_company', 'Work_accident', 'promotion_last_5years',
'department_RandD', 'department_hr', 'department_management', 'salary_high', 'salary_low']
X=hr[cols]
y=hr['left']
Logistic Regression Model
from sklearn.cross_validation import train_test_split
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.3, random_state=0)
from sklearn.linear_model import LogisticRegression
from sklearn import metrics
logreg = LogisticRegression()
logreg.fit(X_train, y_train)
LogisticRegression(C=1.0, class_weight=None, dual=False, fit_intercept=True, intercept_scaling=1, max_iter=100, multi_class=’ovr’, n_jobs=1, penalty=’l2', random_state=None, solver=’liblinear’, tol=0.0001, verbose=0, warm_start=False)
from sklearn.metrics import accuracy_score
print('Logistic regression accuracy: {:.3f}'.format(accuracy_score(y_test, logreg.predict(X_test))))
Точность Logistic Regression Model: 0.771
Random Forest
from sklearn.ensemble import RandomForestClassifier
rf = RandomForestClassifier()
rf.fit(X_train, y_train)
RandomForestClassifier(bootstrap=True, class_weight=None, criterion=’gini’, max_depth=None, max_features=’auto’, max_leaf_nodes=None, min_impurity_split=1e-07, min_samples_leaf=1, min_samples_split=2, min_weight_fraction_leaf=0.0, n_estimators=10, n_jobs=1, oob_score=False, random_state=None, verbose=0, warm_start=False)
print('Random Forest Accuracy: {:.3f}'.format(accuracy_score(y_test, rf.predict(X_test)))) Точность Random Forest: 0,988
Support Vector Machine
from sklearn.svm import SVC
svc = SVC()
svc.fit(X_train, y_train)
SVC(C=1.0, cache_size=200, class_weight=None, coef0=0.0,
decision_function_shape=None, degree=3, gamma=’auto’, kernel=’rbf’,
max_iter=-1, probability=False, random_state=None, shrinking=True,
tol=0.001, verbose=False)
print('Support vector machine accuracy: {:.3f}'.format(accuracy_score(y_test, svc.predict(X_test)))) Точность Support Vector Machine: 0.909
Победитель… Random Forest, так ведь?
Cross Validation (перекрестная проверка)
Перекрестная проверка помогает избежать переобучения во время создания прогноза для каждого набора данных. Мы используем 10-кратную кросс-валидацию для обучения нашей модели Random Forest.
from sklearn import model_selection
from sklearn.model_selection import cross_val_score
kfold = model_selection.KFold(n_splits=10, random_state=7)
modelCV = RandomForestClassifier()
scoring = 'accuracy'
results = model_selection.cross_val_score(modelCV, X_train, y_train, cv=kfold, scoring=scoring)
print("10-fold cross validation average accuracy: %.3f" % (results.mean()))
Средняя точность 10-кратной кросс-валидации 0.977
Данный показатель близок по значению с показателем точности Random Forest.
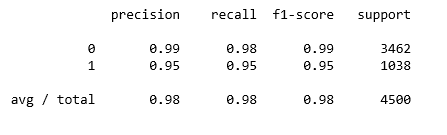
Precision and recall
Мы строим матрицу для того, чтобы визуализировать прогноз, сделанный классификатором, и оцениваем точность классификации.
Random Forest
from sklearn.metrics import classification_report
print(classification_report(y_test, rf.predict(X_test)))
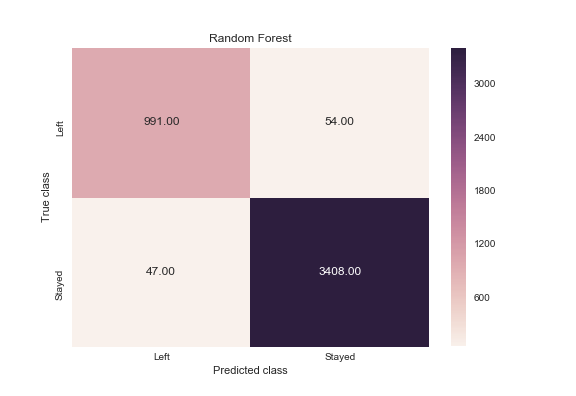
y_pred = rf.predict(X_test)
from sklearn.metrics import confusion_matrix
import seaborn as sns
forest_cm = metrics.confusion_matrix(y_pred, y_test, [1,0])
sns.heatmap(forest_cm, annot=True, fmt='.2f',xticklabels = ["Left", "Stayed"] , yticklabels = ["Left", "Stayed"] )
plt.ylabel('True class')
plt.xlabel('Predicted class')
plt.title('Random Forest')
plt.savefig('random_forest')
Logistic Regression
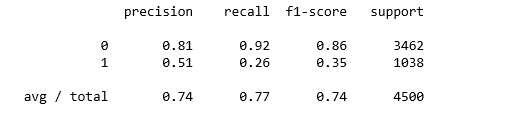
print(classification_report(y_test, logreg.predict(X_test)))
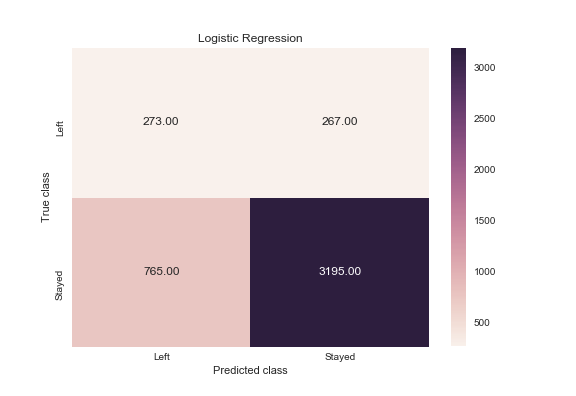
logreg_y_pred = logreg.predict(X_test)
logreg_cm = metrics.confusion_matrix(logreg_y_pred, y_test, [1,0])
sns.heatmap(logreg_cm, annot=True, fmt='.2f',xticklabels = ["Left", "Stayed"] , yticklabels = ["Left", "Stayed"] )
plt.ylabel('True class')
plt.xlabel('Predicted class')
plt.title('Logistic Regression')
plt.savefig('logistic_regression')
Support Vector Machine
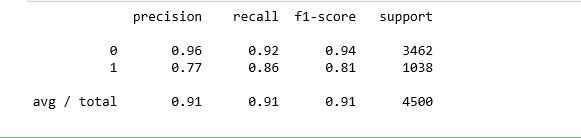
print(classification_report(y_test, svc.predict(X_test)))
svc_y_pred = svc.predict(X_test)
svc_cm = metrics.confusion_matrix(svc_y_pred, y_test, [1,0])
sns.heatmap(svc_cm, annot=True, fmt='.2f',xticklabels = ["Left", "Stayed"] , yticklabels = ["Left", "Stayed"] )
plt.ylabel('True class')
plt.xlabel('Predicted class')
plt.title('Support Vector Machine')
plt.savefig('support_vector_machine')
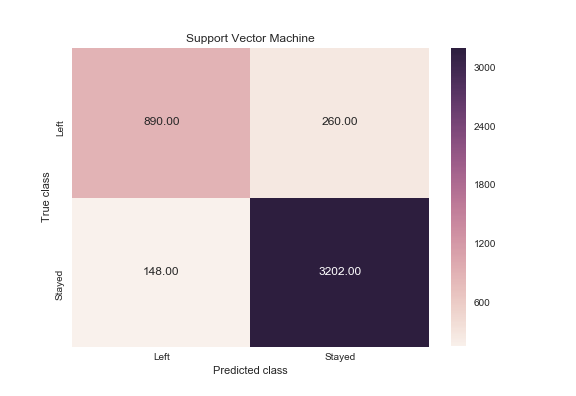
Как часто классификатор может верно предугадать уход сотрудника? Это измерение называется «recall», и быстрый просмотр этих диаграмм дает понять, что random forest подходит явно лучше всего. Из всех случаев сменяемости кадров, random forest сделал правильный прогноз в 991 случае из 1038 (около 95%). В то время как logistic regression 26%, а support vector machines – 85%.
Когда классификатор предсказывает, что сотрудник уйдет, как часто этот сотрудник фактически уходит? Это измерение называется «precision». Random forest снова впереди – около 95% точности (991 из 1045), logistic regression – примерно 51% (273 из 540) и support vector machines – приблизительно 77% (890 из 1150).
Кривая ROC
from sklearn.metrics import roc_auc_score
from sklearn.metrics import roc_curve
logit_roc_auc = roc_auc_score(y_test, logreg.predict(X_test))
fpr, tpr, thresholds = roc_curve(y_test, logreg.predict_proba(X_test)[:,1])
rf_roc_auc = roc_auc_score(y_test, rf.predict(X_test))
rf_fpr, rf_tpr, rf_thresholds = roc_curve(y_test, rf.predict_proba(X_test)[:,1])
plt.figure()
plt.plot(fpr, tpr, label='Logistic Regression (area = %0.2f)' % logit_roc_auc)
plt.plot(rf_fpr, rf_tpr, label='Random Forest (area = %0.2f)' % rf_roc_auc)
plt.plot([0, 1], [0, 1],'r--')
plt.xlim([0.0, 1.0])
plt.ylim([0.0, 1.05])
plt.xlabel('False Positive Rate')
plt.ylabel('True Positive Rate')
plt.title('Receiver operating characteristic')
plt.legend(loc="lower right")
plt.savefig('ROC')
plt.show()
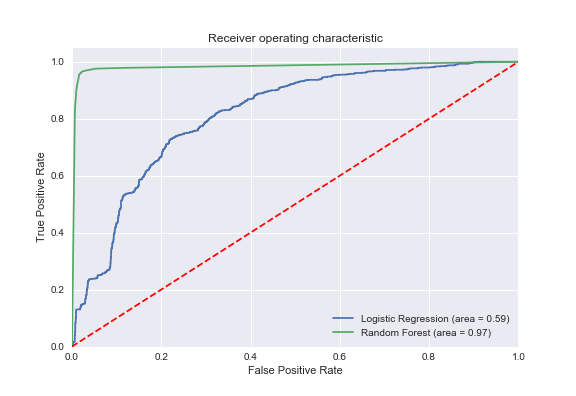
Кривая ROC (receiver operating characteristic) является еще одним распространенным инструментом, используемым с бинарными классификаторами. Пунктирная красная линия представляет собой кривую ROC случайного классификатора. Подходящий классификатор располагается как можно дальше от этой линии (по направлению к верхнему левому углу).
Feature Importance (значимость признаков) для Random Forest Model
feature_labels = np.array(['satisfaction_level', 'last_evaluation', 'time_spend_company', 'Work_accident', 'promotion_last_5years',
'department_RandD', 'department_hr', 'department_management', 'salary_high', 'salary_low'])
importance = rf.feature_importances_
feature_indexes_by_importance = importance.argsort()
for index in feature_indexes_by_importance:
print('{}-{:.2f}%'.format(feature_labels[index], (importance[index] *100.0)))
promotion_last_5years-0.20%
department_management-0.22%
department_hr-0.29%
department_RandD-0.34%
salary_high-0.55%
salary_low-1.35%
Work_accident-1.46%
last_evaluation-19.19%
time_spend_company-25.73%
satisfaction_level-50.65%
Согласно нашей модели Random Forest, выше по возрастанию представлены те признаки, которые влияют на уход сотрудников из компании.
Заключение
И вот мы подошли к концу нашей статьи. Мы не будем распечатывать список сотрудников, которые, по прогнозам модели, могут уйти. Это не является целью данного анализа. Помните, что мы не можем применять этот алгоритм абсолютно для всех. Анализ текучести кадров может помочь найти решение, но не принять его. Используйте аналитику, чтобы избежать правовых аспектов и недоверия сотрудников, а также важно использовать ее вместе с обратной связью сотрудников для принятия наилучших решений.






