Самая мощная идея в Data Science
Быстрый способ отделить зерна от плевел
Если вы пройдете вводный курс по статистике, вы узнаете, что точка данных может быть использована для вдохновения или для проверки теории, но не для того и другого сразу. Почему?

Люди слишком хорошо умеют видеть шаблонные образы во всем. Настоящие образы, придуманные образы, называйте как хотите. Так уж мы устроены, что видим лицо Элвиса в картофельных чипсах. Если вы склонны принимать желаемое за действительное, помните, что существует три типа шаблонов данных:
- Шаблоны/факты, которые существуют в вашем наборе данных и за его пределами.
- Шаблоны/факты, которые существуют только в вашем наборе данных.
- Шаблоны/факты, которые существуют только в вашем воображении (апофения).
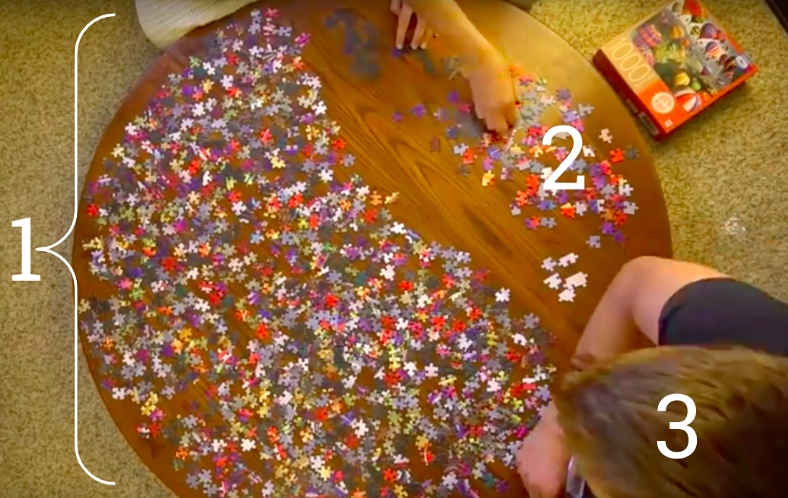 Шаблон данных может существовать (1) во всем рассматриваемом множестве, (2) только в выборке данных или (3) только в вашей голове. Источник.
Шаблон данных может существовать (1) во всем рассматриваемом множестве, (2) только в выборке данных или (3) только в вашей голове. Источник.
Какие из них вам нужны? Все зависит от ваших целей.
Вдохновение
Если вы стремитесь к чистому вдохновению, все они прекрасны. Даже странная апофения — от термина apophenia (склонность человека ошибочно видеть взаимосвязи и структуру между несвязанными, случайными данными) — может привести в движение вашу творческую энергию. В творчестве нет верных и неверных ответов, поэтому все, что вам нужно сделать, это посмотреть на ваши данные и поиграйте с ними. В качестве дополнительного бонуса постарайтесь не тратить слишком много времени (своего или вашего стейкхолдера) на этот процесс.
Факты
Когда ваше правительство хочет собрать с вас налоги, меньше всего его заботят процессы, выходящие за границы ваших финансовых данных за год. Необходимо принять решение на основе фактов о том, сколько вы должны заплатить, и чтобы это сделать, нужно проанализировать данные за прошлый год. Другими словами, посмотри на данные и примените формулу. Для этого нужна только дескриптивная аналитика (descriptive analytics), которая опирается на имеющиеся данные. Для данного случая подходит любой из первых двух типов шаблонов.
Дескриптивная аналитика, которая опирается на имеющиеся данные.
(Я никогда не теряла свои финансовые отчеты, но, полагаю, что правительство Соединенных Штатов было бы не в восторге, если бы в ситуации их потери я решила использовать методы условного расчета, которые выучила в магистратуре, для статистической уплаты своих налогов).
Решения в условиях неопределенности
Случается, что факты, которые у вас есть, не совпадают с фактами, которые вы хотели бы иметь. Если вы не обладаете всей информацией, необходимой для принятия решения, которое вы хотели бы принять, вам придется двигаться в неопределенности в попытках выбрать разумный курс действий.
Суть статистики — науки менять принятые решения условиях неопределенности — именно в этом. В этой игре нужно совершить прыжок, подобно Икару, за пределы того, что вы знаете ... и не разбиться при этом в лепешку.
Большая проблема, лежащая в основе науки о данных: как в результате изучения данных не оказаться *менее* информированным.
Бросаясь в пропасть, молитесь, чтобы шаблоны, которые вы нашли через свое субъективное восприятие реальности, работали и за его пределами. Иными словами, чтобы шаблоны работали, их нужно генерализировать.
 Источник: xkcd
Источник: xkcd
Из трех вариантов надежен только первый (генерализированный) тип шаблона, когда вам приходится принимать решения в условиях неопределенности. К сожалению, вы столкнетесь и с другими типами шаблонов в своих данных — это большая проблема, лежащая в основе науки о данных: как в результате изучения данных не оказаться менее информированным.
Генерализация
Если вы думаете, что выводить непригодные шаблоны из данных присуще только человеческому виду, то вы заблуждаетесь! Системы могут автоматизировать ту же глупость, если вы не будете осторожны.
Весь смысл ML/AI - правильно производить генерализацию в каждом новом случае.
Machine Learning - это способ решать множество аналогичных задач, который включает алгоритмический поиск шаблонов в ваших данных и их использование для правильного реагирования на новые данные. В жаргоне ML/AI генерализация относится к способности вашей модели хорошо взаимодействовать с данными, которых она раньше не видела. Что хорошего в шаблонном процессе, который эффективен только для устаревших моделей? Вы можете просто использовать таблицу поиска для этого. Истинное назначение ML/AI в корректной генерализации к новым ситуациям.

Именно поэтому единственный тип шаблонов в нашем списке, который подходит для Machine Learning — первый. Такой элемент является сигналом, остальное — просто шум (ложный след, который существует только в ваших старых данных и мешает вам создавать генерализованную модель).
Сигнал: Шаблоны, которые существуют в вашем наборе данных и за его пределами. Шум: Шаблоны, которые существуют только в вашем наборе данных.
По сути, найти решение, которое обрабатывает старый шум вместо новых данных, это то, что в Machine Learning обозначается термином «переобучение» («overfitting»). (Мы произносим это слово тем же тоном, каким бы вы сказали свое любимое крепкое словцо.) Практически все, что мы делаем в Machine Learning, служит как раз для того, чтобы избежать переобучения.
Так какой же шаблон — тот самый?
Допустим, шаблон, который вы (или ваша система) вывели из ваших данных, существует вне вашего воображения, какого он типа? Является ли это реальным явлением, которое существует в интересующем вас множестве («сигнал»), или особенностью вашего текущего набора данных («шум»). Как вы сможете определить, какой шаблон вы обнаружили во время своей вылазки в набор данных?
Если вы просмотрите все доступные вам данные – точно не сможете. Вы увязнете и уже не сможете понять, существует ли ваш шаблон где-то ещё. Вся риторика статистической проверки гипотез зиждется на неожиданностях, и было бы моветоном прикидываться, что вас удивляет появление закономерности, о которой вы уже знаете, в ваших данных. (По сути, это p-hacking.)

Это то же самое, что увидеть в форме одного из облаков кролика, а потом проверять, все ли облака похожи на кроликов, ...используя одно и то же облако. Надеюсь, вы понимаете, что вам понадобятся какие-то ещё облака для проверки своей теории.
Никакая точка данных, которую вы используете, чтобы сформулировать какую-то теорию или вопрос, не может быть использована для проверки этой же теории.
Что бы вы могли сделать, если бы знали, что у вас есть доступ только к одному изображению из всего облака данных? Медитировать в шкафу – и больше ничего. Формулируйте свой вопрос, прежде чем изучать данные.
Математика никогда не противоречит основам здравого смысла.
И вот мы приходим к самому печальному выводу. Если вы используете свой набор данных для поисков собственного вдохновения, вы не сможете использовать его снова, чтобы тщательно протестировать теорию, которую он помог сформулировать (вне зависимости от того, какие математические трюки вы выкидывали, ведь математика никогда не противоречит основам здравого смысла).
Трудный выбор
Все это значит, что вы должны выбрать! Если у вас есть только один набор данных, придется спросить себя: «Я медитирую в шкафу, ограничиваю все свои предположения областью статистического тестирования, а затем придерживаюсь сугубо строгого подхода, чтобы я мог относиться к себе серьезно? Или я вывожу данные просто для вдохновения, и осознаю при этом, что, возможно, обманываю себя и не забываю использовать фразы типа «мне кажется», «это вселяет чувство» или «я не уверен»? Трудный выбор!
Или есть способ усидеть на двух стульях? Проблема в том, что у вас есть только один набор данных, а нужно несколько. Если у вас много данных, у меня есть для вас фокус, который. Взорвет. Ваш. Мозг.

Одна странная штука
Чтобы стать победителем в Data Science, просто превратите один набор данных в (хотя бы) два, разделив ваши данные. Затем один используйте для вдохновения, а другой для тщательного тестирования. Если шаблон, который вдохновил вас изначально, существует также и в данных, которые не могли повлиять на ваш взгляд, то это более обнадеживающий голос в пользу того, что шаблон является общим местом для всего аквариума, откуда вы вытащили свои данные.
Если одно и то же явление существует в обоих наборах данных, возможно, это общее явление, которое существует вне зависимости от того, откуда были взяты эти наборы данных.
SYDD!
Если неизученная жизнь не стоит того, чтобы жить, то вот четыре слова, которыми нужно руководствоваться: Разбей Свои Долбанные Данные (Split Your Damned Data).
Мир был бы лучше, если бы каждый разбивал свои данные. Мы бы получали лучшие ответы (из статистики) на лучшие вопросы (из аналитики). Единственная причина, по которой люди не воспринимают разделение данных как совершенно необходимую привычку, заключается в том, что в прошлом веке это была роскошь, которую могли себе позволить лишь немногие; наборы данных были настолько малы, что если вы попытаетесь их еще и разделить, то ничего не останется. (Почитайте об истории Data Science здесь).
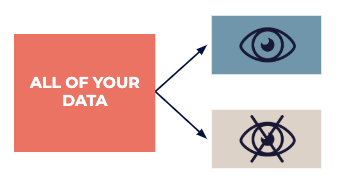 Разбейте свои данные на набор данных для исследований, где все смогут черпать вдохновение, и набор данных для проверки, который позже будет использоваться экспертами для строгого подтверждения любых «выводов», возникших на этапе исследования.
Разбейте свои данные на набор данных для исследований, где все смогут черпать вдохновение, и набор данных для проверки, который позже будет использоваться экспертами для строгого подтверждения любых «выводов», возникших на этапе исследования.
Некоторые проекты до сих пор сталкиваются с этой проблемой, особенно в медицинских исследованиях (раньше я занималась нейробиологией, поэтому я с большим уважением отношусь к сложности работы с небольшими наборами данных), но у многих из вас так много данных, что приходится нанимать грузчиков, чтобы все это перетаскивать... каково ваше оправдание?! Не скупитесь и разделите данные.
Если вы не привыкли разбивать данные, есть вероятность, что вы застряли в XX веке.
Если данные у вас водятся пачками, но вы все еще видите неразделенные наборы данных, значит, ваша глухомань страдает от старомодной перспективы. Все привыкли к архаичному мышлению и забыли, что время не стоит на месте.
Machine Learning — продукт разделения данных
Так или иначе, идея очень проста. Один набор данных используйте, чтобы сформулировать теорию, выдвинуть предположения, а затем исполнить фокус, чтобы доказать, что вы знаете, о чем говорите, на новом наборе данных.
Разделение данных — это самое простое и быстрое решение для жизнеспособной культуры данных.
Таким образом, вы сохраняете безопасность в статистике, да еще и избегаете риска быть заживо съеденными переобучением в ML/AI. Фактически, история Machine Learning - это история разделения данных. (Объясняю, почему в Machine Learning есть автоматизированное вдохновение.)
Как же использовать лучшую идею в Data Science
Чтобы воспользоваться преимуществами лучшей идеи в Data Science, все, что вам нужно сделать, — убедиться, что часть тестовых данных находятся вне досягаемости любопытных глаз, а затем позволить своим аналитикам поиграть с остальным.
Чтобы стать победителем в Data Science, просто превратите один набор данных в (хотя бы) два, разделив ваши данные.
Когда вам покажется, что они принесли вам дельные выводы, выходящие за рамки информации, которую они исследовали, используйте свой секретный набор тестовых данных, чтобы проверить их результаты. Вот и все!