Распространенные мифы, которых следует опасаться в Data Science и машинном обучении
Что такое машинное обучение: Data Science или искусственный интеллект? Это один из самых распространенных вопросов, который мне задают. Этот вопрос ставит в тупик и начинающих пользователей, и специалистов по подбору персонала, и даже руководителей.
Начинающих пользователей волнует, как стать специалистом по обработке и анализу данных; руководители задаются вопросом, насколько важное влияние оказывает Data Science на бизнес. Люди, работающие в этой сфере, не могут определиться, как себя называть: Data Scientist, Data Engineer или Data Analyst.
В этом посте я попытаюсь прояснить некоторые мифы и дать общее понятие о том, что такое Data Science, и как ее интерпретируют в деловом мире.
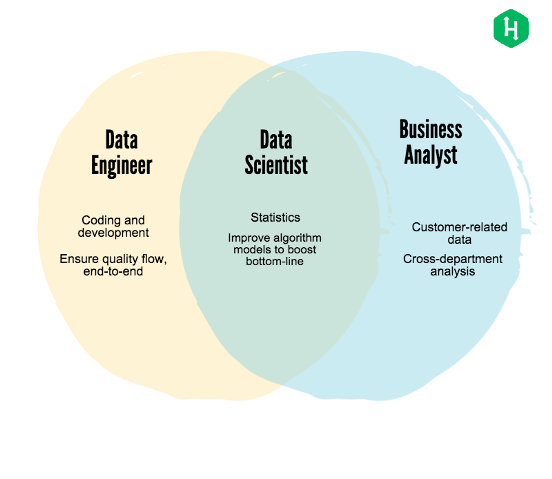
Миф 1: Data Scientist/Engineer/Analyst – это одно и то же.
Это искаженный миф, с которым я сталкивался много раз в своей карьере и который вредит как сотруднику, так и компании. Это все равно, что QA-инженера (специалиста по функциональному тестированию программного обеспечения на этапе разработки) называть инженером-программистом.
В широком смысле Data Scientist – это тот, кто имеет опыт и знания, как минимум, в двух из трех областей: статистики, программирования и машинного обучения. Такой сотрудник хочет работать над сложной бизнес-задачей, где он может использовать свои знания для поиска решений. Он стремится потратить бóльшую часть своей работы для создания предиктивных моделей и проведения статистических экспериментов, чтобы получить бизнес-решение. Это смесь исследовательской работы и программирования, а характер работы и нагрузка различаются в зависимости от размера компании/команды.
Data Engineering – это работа, в которой человек сосредотачивается на создании инфраструктуры для запуска приложений, выполняющих такие задания, как: предиктивное моделирование, обновление панелей потоковой передачи данных, выполнение ежедневных заданий для создания отчетов и поддержание непрерывного потока данных. Хороший инженер данных должен знать SQL (язык структурированных запросов) и Spark (программную платформу распределенной обработки данных).
Data Analyst – это человек, который больше склонен к интерпретации и анализу бизнес-результатов, а не к процессу их создания. Такой человек предпочитает использовать инструменты для получения этих результатов и будет тратить бóльшую часть своего времени на интерпретацию и извлечение из них ценности для бизнеса. Аналитики данных были в этой отрасли задолго до того, как туда пришли исследователи данных, и основным инструментом выбора тогда был Excel. На самом деле, даже сегодня для небольшого объема данных Excel является наиболее эффективным инструментом. В настоящее время также используются такие инструменты, как PowerBI, Azure, которые предоставляют возможность выполнять аналитику большого объема данных. Основное внимание, однако, уделяется точному сообщению ежедневных результатов, а также результатов новой проверяемой гипотезы. Эти входные данные и формируют основание для важного принятия решений в бизнесе.
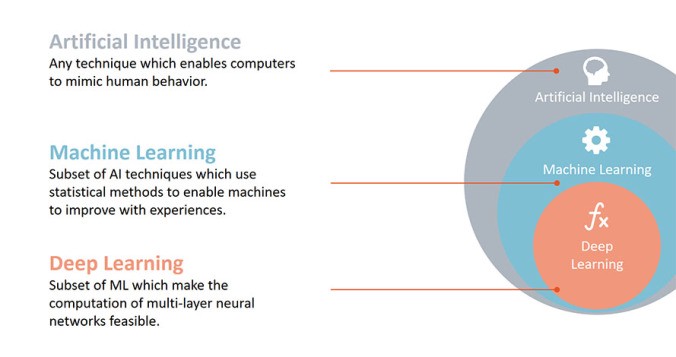
Миф 2: Глубокое обучение – это машинное обучение или искусственный интеллект
Благодаря маркетингу и шумихе вокруг него, о глубоком обучении сегодня знают многие. Как следствие, люди считают, что глубокое обучение может решить любую проблему в области Data Science или машинного обучения.
Глубокое обучение, несомненно, является одним из самых сложных понятий в современном машинном обучении, которые следует уяснить. Глубокое обучение получило свое название из-за того, что «нейронная сеть», подразумеваемая в его структуре, имеет несколько уровней и поэтому называется «глубокой» сетью. То, что предлагается через tensorflow, pytorch или keras, – просто основа для применения этой концепции.
Фреймворк достаточно сложен для изучения. Он эффективен, но не эквивалентен опыту, полученному в машинном обучении. Машинное обучение – это огромное поле, в котором используются концепции и алгоритмы из целого ряда областей: статистики, теории информации, оптимизации, поиска информации, нейронных сетей и т.д., и имеет множество алгоритмов, каждый из которых может быть полезен в конкретных случаях его использования.
Глубокое обучение, например, было очень эффективно в машинном зрении и распознавании речи, но его использование в анализе тональности высказываний или простой задаче прогнозирования, которая может быть решена с помощью линейной регрессии, является абсолютно лишним.
Разумно потратить время на исследовательский анализ и понимание масштабов проблемы до того, как использовать алгоритм, для решения конкретной проблемы.
Миф 3: Data Science нельзя изучить за 3 месяца
Как бы мне ни хотелось, чтобы это было неправдой, но это не так. Чтобы стать Data Scientist, нужно знать гораздо больше импортирования библиотеки через «scikit-learn» и «tensorflow».
Это одна из тех областей, где результаты не детерминированы, то есть одна и та же последовательность шагов не всегда ведет к одному и тому же результату. Все зависит от качества и количества предоставленных данных, а перед вызовом функции «train» следует совершить много действий.
Конечно, вы можете научиться импортировать библиотеки и записывать последовательность шагов для создания модели, но эта модель не всегда будет эффективной. Однако нужно понимать принцип работы и зависимости применяемого алгоритма. Крайне важно это знать, иначе настройка моделей или объяснение результатов руководству будет сопряжено с рядом проблем.
Вот так я всегда объясняю, когда меня спрашивают, как научиться кодированию за одну ночь.
Это небольшая попытка подчеркнуть и прояснить распространенные мифы в области машинного обучения и Data Science. Надеюсь, поможет.
Оригинал статьи: General Myths to avoid in Data Science and Machine Learning






