Плавное введение в Natural Language Processing (NLP)
Введение в NLP с Sentiment Analysis в текстовых данных.
Люди общаются с помощью каких-либо форм языка и пользуются либо текстом, либо речью. Сейчас для взаимодействия компьютеров с людьми, компьютерам необходимо понимать естественный язык, на котором говорят люди. Natural language processing занимается как раз тем, чтобы научить компьютеры понимать, обрабатывать и пользоваться естественными языками.
В этой статье мы рассмотрим некоторые частые методики, применяющиеся в задачах NLP. И создадим простую модель сентимент-анализа на примере обзоров на фильмы, чтобы предсказать положительную или отрицательную оценку.
Что такое Natural Language Processing (NLP)?
NLP — одно из направлений искуственного интеллекта, которое работает с анализом, пониманем и генерацией живых языков, для того, чтобы взаимодействовать с компьютерами и устно, и письменно, используя естественные языки вместо компьютерных.
Применение NLP
- Machine translation (Google Translate)
- Natural language generation
- Поисковые системы
- Спам-фильтры
- Sentiment Analysis
- Чат-боты
… и так далее
Очистка данных (Data Cleaning):
При Data Cleaning мы удаляем из исходных данных особые знаки, символы, пунктуацию, тэги html <> и т.п., которые не содержат никакой полезной для модели информации и только добавляют шум в данные.
Что удалять из исходных данных, а что нет зависит от постановки задачи. Например, если вы работаете с текстом из сферы экономики или бизнеса, знаки типа $ или другие символы валют могут содержать скрытую информацию, которую вы не хотите потерять. Но в большинстве случаев, мы их удаляем.
 Код на Python: Data cleaning
Код на Python: Data cleaning
Предварительная обработка данных (Preprocessing of Data)
Preprocessing of Data это этап Data Mining, который включает в себя трансформацию исходных данных в доступный для понимания формат.
Изменение регистра:
Одна из простейших форм предварительной обработки текста — перевод всех символов текста в нижний регистр.
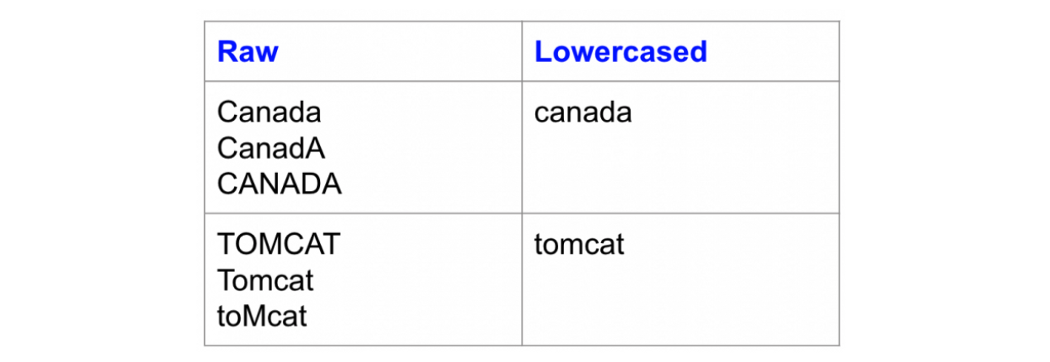
 Код на Python: перевод в нижний регистр
Код на Python: перевод в нижний регистр
Токенизация:
Токенизация — процесс разбиения текстового документа на отдельные слова, которые называются токенами.
 Код на Python: Токенизация
Код на Python: Токенизация
Как можно видеть выше, предложение разбито на слова (токены).
Natural language toolkit (библиотека NLTK) — популярный открытый пакет библиотек, используемых для разного рода задач NLP. В этой статье мы будем использовать библиотеку NLTK для всех этапов Text Preprocessing.
Вы можете скачать библиотеку NLTK с помощью pip:
!pip install nltk
Удаление стоп-слов:
Стоп-слова — это часто используемые слова, которые не вносят никакой дополнительной информации в текст. Слова типа "the", "is", "a" не несут никакой ценности и только добавляют шум в данные.
В билиотеке NLTK есть встроенный список стоп-слов, который можно использовать, чтобы удалить стоп-слова из текста. Однако это не универсальный список стоп-слов для любой задачи, мы также можем создать свой собствпнный набор стоп-слов в зависимости от сферы.
 Код на Python: Удаление стоп-слов
Код на Python: Удаление стоп-слов
В библиотеке NLTK есть заранее заданный список стоп-слов. Мы можем добавитьили удалить стоп-слова из этого списка или использовать его в зависимости от конкретной задачи.
Стеммизация:
Стеммизация — процесс приведения слова к его корню/основе.
Он приводит различные вариации слова (например, "help", "helping", "helped", "helpful") к его начальной форме (например, "help"), удаляет все придатки слов (приставка, суффикс, окончание) и оставляет только основу слова.
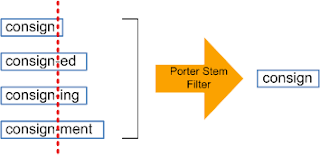
 Код на Python: Стеммизация
Код на Python: Стеммизация
Корень слова может быть существующим в языке словом, а может и не быть им. Например, "mov" корень слова "movie", "emot" корень слова "emotion".
Лемматизация:
Лемматизация похожа на стеммизацию в том, что она приводит слово к его начальной форме, но с одним отличием: в данном случае корень слова будет существующим в языке словом. Например, слово "caring" прекратится в "care", а не "car", как в стеммизаци.
 Код на Python: Лемматизация
Код на Python: Лемматизация
WordNet — это база существующих в английском языке слов. Лемматизатор из NLTK WordNetLemmatizer() использует слова из WordNet.
N-граммы:
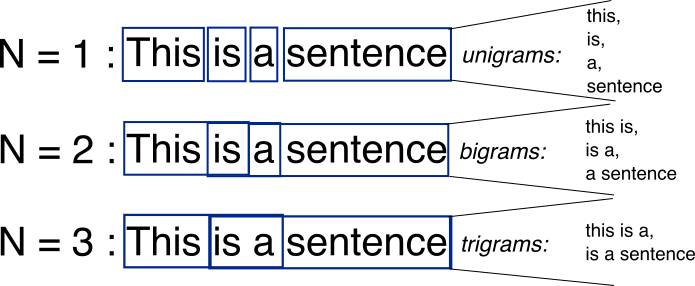
N-граммы — это комбинации из нескольких слов, использующихся вместе, N-граммы, где N=1 называются униграммами (unigrams). Подобным же образом, биграммы (N=2), триграммы (N=3) и дальше можно продолдать аналогичным способом.
N-граммы могут использоваться, когда нам нужно сохранить какую-то последовательность данных, например, какое слово чаще следует за заданным словом. Униграммы не содержат никкой последовательности данных, так как каждое слово берется индивидуально.
Векторизация текстовых данных (Text Data Vectorization):
Процесс конвертации текста в числа называется векторизацией. Теперь после Text Preprocessing, нам нужно представить текст в числовом виде, то есть закодировать текстовые данные в виде чисел, которые в дальнейшем могут использоваться в алгоритмах.
«Мешок слов» (Bag of words (BOW)):
Это одна из самых простых методик векторизации текста. В логике BOW два предложения могут называться одинаковыми, если содержат один и тот же набор слов.
Рассмотрим два предложения:

В задачах NLP, каждое текстовое предложение называется документом, а несколько таких документов называют корпусом текстов.
BOW создает словарь уникальных d слов в корпусе (собрание всех токенов в данных). Например, корпус на изображении выше состоит из всех слов предложений S1 и S2.
Теперь мы можем создать таблицу, где столбцы соответствуют входящим в корпус уникальным d словам, а строки предложениям (документам). Мы устанавливаем значение 1, если слово в предложении есть, и 0, если его там нет.

Это позволит создать dxn матрицу, где d это общее число уникальных токенов в корпусе и n равно числу документов. В примере выше матрица будет иметь форму 11x2.
TF-IDF:

Это расшифровывается как Term Frequency (TF)-Inverse Document Frequency (IDF).
Частота слова (Term Frequency):
Term Frequency высчитывает вероятность найти какое-то слово в документе. Ну, например, мы хотим узнать, какова вероятрность найти слово wi в документе dj.
Term Frequency (wi, dj) =
Количество раз, которое wi встречается в dj / Общее число слов в dj
Обратная частота документа (Inverse Document Frequency):
В логике IDF, если слово встречается во всех документах, оно не очень полезно. Так определяется, насколько уникально слово во всем корпусе.
IDF(wi, Dc) = log(N/ni)
Здесь Dc = Все документы в корпусе,
N = Общее число документов,
ni = документы, которые содержат слово (wi).
Если wi встречается в корпусе часто, значение IDF снижается.
Если wi используется не часто, то ni снижается и вследствие этого значение IDF возрастает.
TF(wi, dj) * IDF(wi, Dc)
TF-IDF — умножение значений TF и IDF. Больший вес получат слова, которые встречаются в документе чаще, чем во всем остальном корпусе.
Sentiment Analysis: Обзоры фильмов на IMDb

Краткая информация
Набор данных содержит коллекцию из 50 000 рецензий на сайте IMDb, с равным количеством положительных и отрицательных рецензий. Задача — предсказать полярность (положительную или отрицательную) данных отзывов (тексты).
1. Загрузка и исследование данных
Набор данных IMDB можно скачать здесь.
Обзор набора данных:
 Положительные рецензии отмечены 1, а отрицательные 0.
Положительные рецензии отмечены 1, а отрицательные 0.
Пример положительной рецензии:

Пример отрицательной рецензии:

2. Data Preprocessing
 На этом этапе мы совершаем все шаги очистки и предварительной обработки данных тем методом, который был описан выше. Мы используем лемматизацию, а не стеммизацию, потому что в процессе тестирования результатов обоих случаев лемматизация дает лучшие результаты, чем стеммизация.
На этом этапе мы совершаем все шаги очистки и предварительной обработки данных тем методом, который был описан выше. Мы используем лемматизацию, а не стеммизацию, потому что в процессе тестирования результатов обоих случаев лемматизация дает лучшие результаты, чем стеммизация.
Использовать ли стеммизацию или лемматизацию или и то, и другое — зависит от поставленной задачи, так что нам стоит попробовать и решить, какой способ сработает лучше для данной задачи.
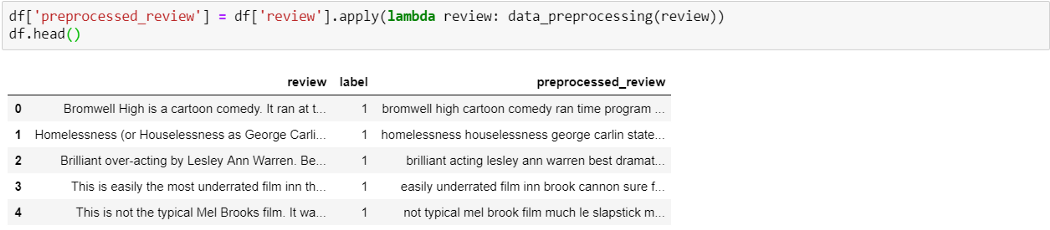
Добавляем новую колонку preprocessed_review в dataframe, применяя data_preprocessing() ко всем рецензиям.
3. Vectorizing Text (рецензии)
Разделяем набор данных на train и test (70–30):

Используем train_test_split из sklearn, чтобы разделить данные на train и test. Здесь используем параметр stratify,чтобы иметь равную пропорцию классов в train и test.
BOW

Здесь мы использовали min_df=10, так как нам нужны были только те слова, которые появляются как минимум 10 раз во всем корпусе.
TF-IDF

4. Создание классификаторов ML
Наивный байесовский классификатор (Naive Bayes) с рецензиями, закодированными BOW

Naive Bayes c BOW выдает точность 84.6%. Попробуем с TF-IDF.
Наивный байесовский классификатор (Naive Bayes) с рецензиями, закодированными TF-IDF

TF-IDF выдает результат немного лучше (85.3%), чем BOW. Теперь давайте попробуем TF-IDF с простой линеарной моделью, Logistic Regression.
Logistic Regression с рецензиями, закодированными TF-IDF

Logistic Regression с рецензиями, закодированными TF-IDF, выдает результат лучше, чем наивный байемовский — точность 88.0%.
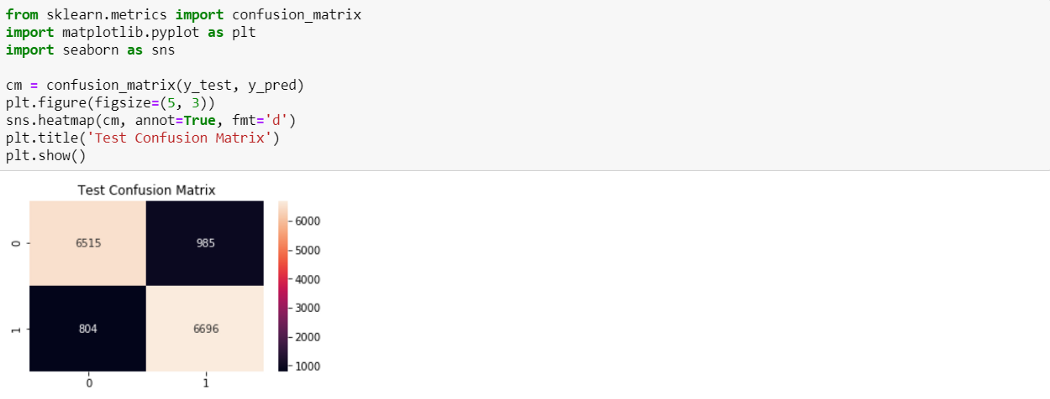 Построение матрицы неточностей даст нам информацию о том, сколько точек данных верны и сколько неверны, классифицированную с помощью модели.
Построение матрицы неточностей даст нам информацию о том, сколько точек данных верны и сколько неверны, классифицированную с помощью модели.
Из 7500 отрицательных рецензий 6515 были верно классифицированы как отрицательные и 985 были неверно классифицированы как положительные. Из 7500 положительных рацензий 6696 были верно классифицированы как положительные, и 804 неверно классифицированы как отрицательные.
Итоги
Мы узнали основные задачи NLP и создали простые модели ML для сентимент-анализа рецензий на фильмы. В дальнейшем усоверешенствований можно добиться с помощью Word Embedding с моделями Deep Learning.
Благодарю за внимание! Полный код смотрите здесь.
Ссылки:
- Ultimate guide to deal with Text Data (using Python) – for Data Scientists and Engineers
- All you need to know about text preprocessing for NLP and Machine Learning
- Applied Course