Комплексное руководство по сверточным нейронным сетям для чайников
В сфере Искусственного интеллекта наблюдается стремительный рывок в устранении разрыва между возможностями человека и машин. И ученые, и любители, работая над многочисленными проблемами в этой области, делают удивительные вещи. Одним из многих таких направлений является Computer Vision (компьютерное зрение).
Повестка дня в этой области состоит в том, чтобы дать возможность машинам видеть мир так, как это делают люди, воспринимать его схожим образом и даже использовать знания для множества задач, таких как Распознавание Изображений и Видео, Анализ и Классификация Изображений, Восстановление Медиа, Системы Рекомендаций, Обработка Естественного языка и т.д. Достижения в области Computer Vision и Deep Learning были разрабатывались и совершенствовались с течением времени, главным образом благодаря совершенно конкретному алгоритму — Сверточной нейронной сети (Convolutional Neural Network).
Введение
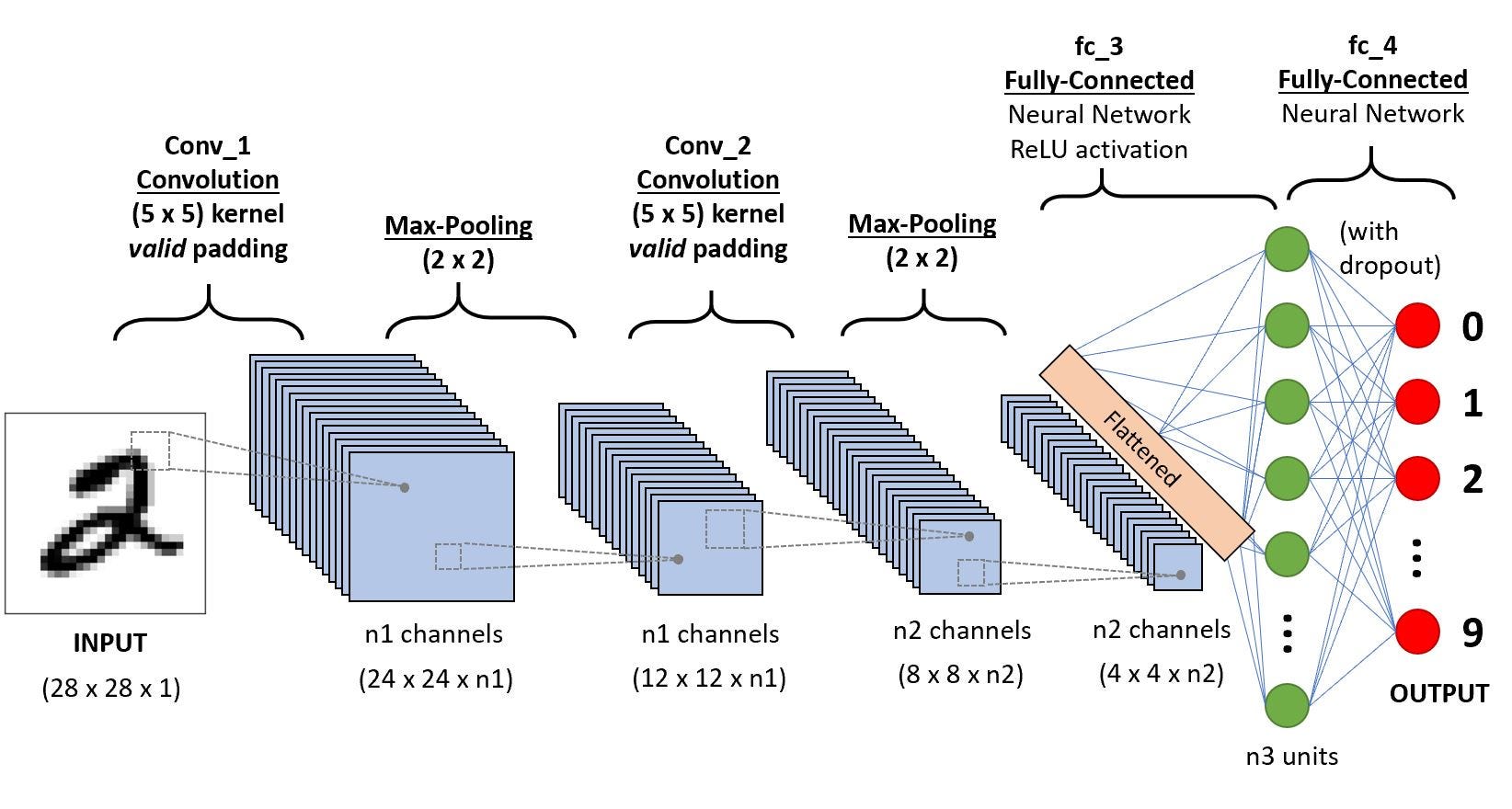 CNN-последовательность для классификации рукописных цифр
CNN-последовательность для классификации рукописных цифр
Сверточная нейронная сеть (Convolutional Neural Network — ConvNet/CNN) — это Deep Learning-алгоритм, который может принимать входное изображение, присваивать важность (усваиваемые веса и смещения) различным областям/объектам в изображении и может отличать одно от другого. Предварительной обработки в ConvNet требуется значительно меньше по сравнению с другими алгоритмами классификации. В то время как в примитивных методах фильтры сконструированы вручную, ConvNets при достаточном обучении способны изучать эти фильтры/характеристики.
Архитектура ConvNet схожа с архитектурой связности нейронов в человеческом мозге и была вдохновлена организацией зрительной коры. Отдельные нейроны реагируют на раздражители только в ограниченной зоне поля зрения, известной как рецептивное поле. Совокупность таких полей накладывается, чтобы покрыть всю зону поля зрения.
ConvNets или Feed-Forward Neural Nets (FF, FFNN — Нейронные сети прямого распространения)?
 Сглаживание матрицы изображения 3х3 по вектору 9х1
Сглаживание матрицы изображения 3х3 по вектору 9х1
На изображении не что иное, как матрица пиксельных значений, верно? Так почему бы просто не сгладить изображение (например, матрицу изображения 3x3 по вектору 9x1) и передать его в многослойный персептрон для классификации? Ну… Все не так просто.
В случае очень простых двоичных изображений этот метод может показывать среднюю оценку точности при прогнозировании классов, но когда речь идет о сложных изображениях, имеющих повсеместную зависимость от пикселей, ни о какой точности не может идти и речи.
ConvNet хорошо умеет захватывать пространственно-временные зависимости в изображении с помощью соответствующих фильтров. Архитектура обеспечивает лучшее совпадение с набором данных изображения благодаря уменьшению количества задействованных параметров и возможности повторного использования весов. Другими словами, сеть можно научить лучше понимать сложность изображения.
Входное изображение
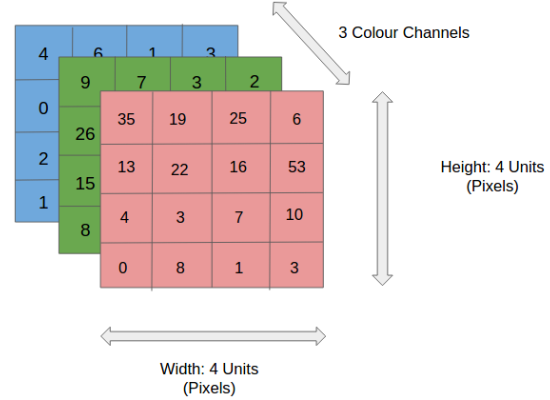 RGB-картинка 4x4x3
RGB-картинка 4x4x3
На рисунке у нас есть RGB-изображение, разделенное по трем цветовым плоскостям — красной, зеленой и синей. Существует несколько таких цветовых пространств, в которых существуют изображения: Grayscale (оттенки серого), RGB, HSV, CMYK и т.д.
Можете представить, что станет с вычислительными ресурсами, когда изображения достигнут размеров, скажем, 8K (7680 × 4320). ConvNet нужен, чтобы преобразовать изображения в ту форму, которую легче обрабатывать без потери характеристик, которые имеют решающую роль для получения хорошего прогноза. Это важно, когда мы хотим разработать архитектуру, которая будет не просто хороша в обучении, но еще и масштабируема для массивных наборов данных.
Сверточный слой — Кернел (the kernel)
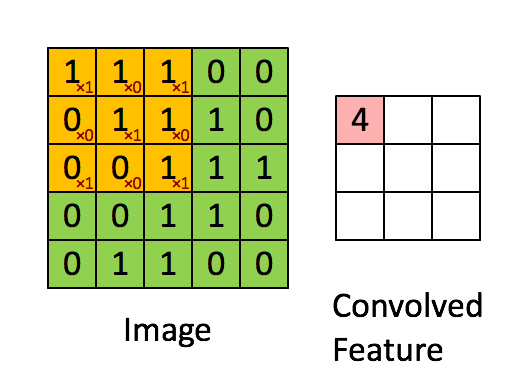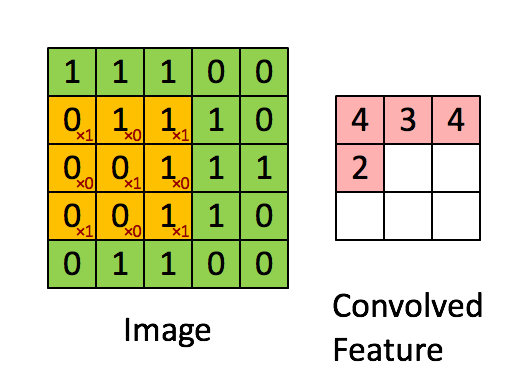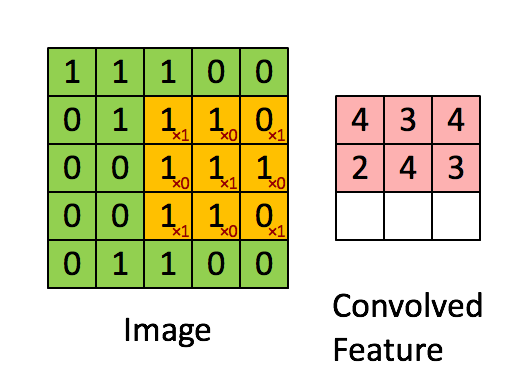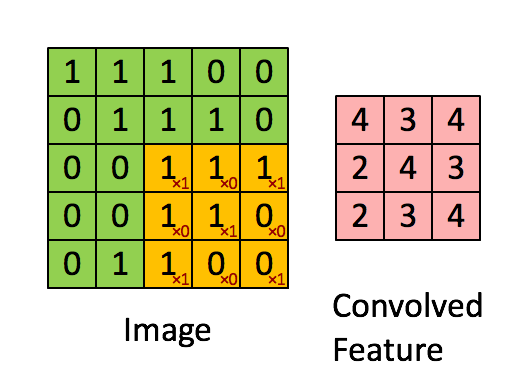 Свертывание изображения 5x5x1 с кернелом размерностью 3x3x1 для получения свернутой функции 3x3x1
Свертывание изображения 5x5x1 с кернелом размерностью 3x3x1 для получения свернутой функции 3x3x1
Размеры изображения = 5 (высота) x 5 (ширина) x 1 (количество каналов, например, RGB)
На гифке выше видно, что зеленая часть напоминает наше входное изображение 5x5x1, I. Элемент, участвующий в выполнении операции свертки в первой части сверточного слоя, называется кернелом/фильтром, K, показан желтым цветом. Мы выбрали K в качестве матрицы 3x3x1.
Кернел/Фильтр, К =1 0 10 1 01 0 1
Кернел смещается 9 раз, так как длина страйда (Stride) = 1, каждый раз выполняя операцию умножения матриц между K и частью P изображения, над которым кернел зависает.
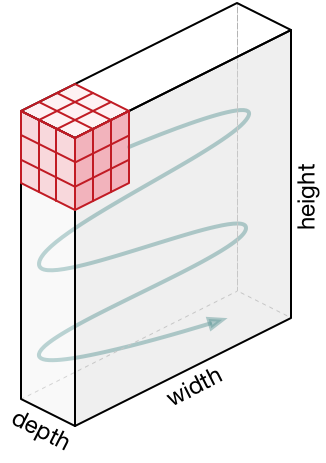 Передвижение кернела
Передвижение кернела
Фильтр двигается вправо с определенным значением страйда до тех пор, пока он не проанализирует всю ширину. Двигаясь дальше, он переходит к началу (слева) изображения с тем же значением шага и повторяет процесс до тех пор, пока не будет пройдено все изображение.
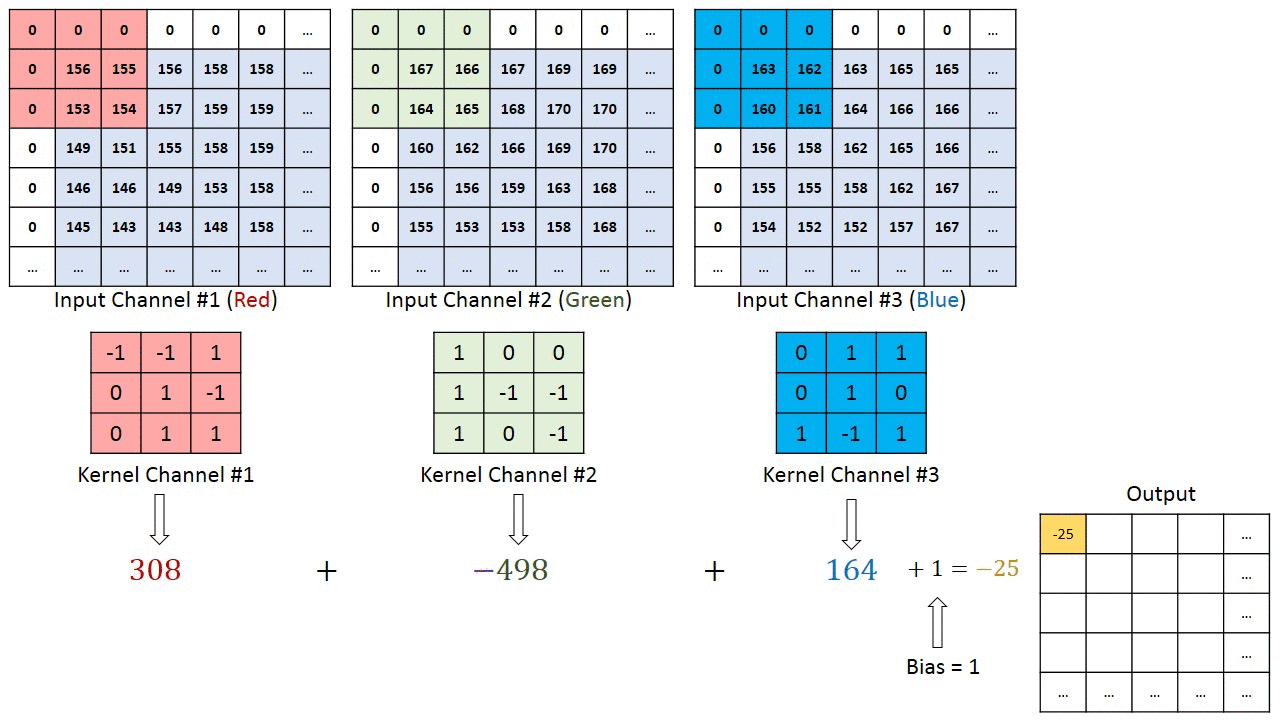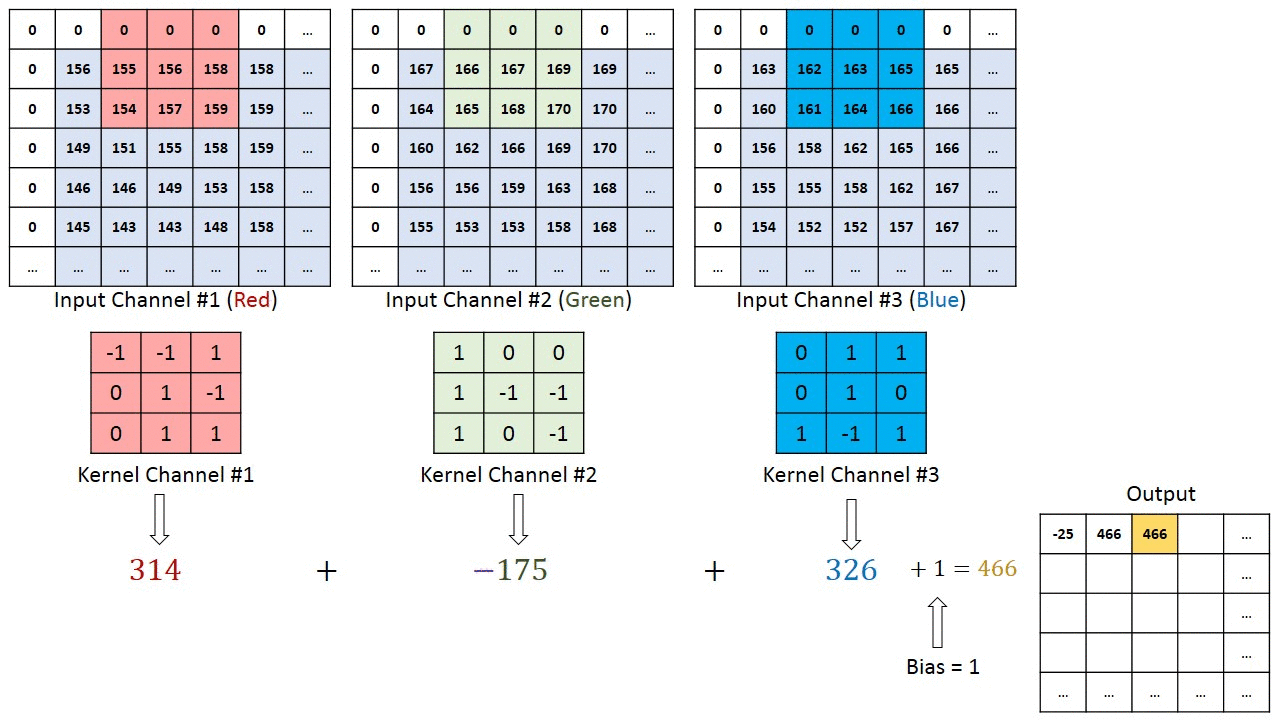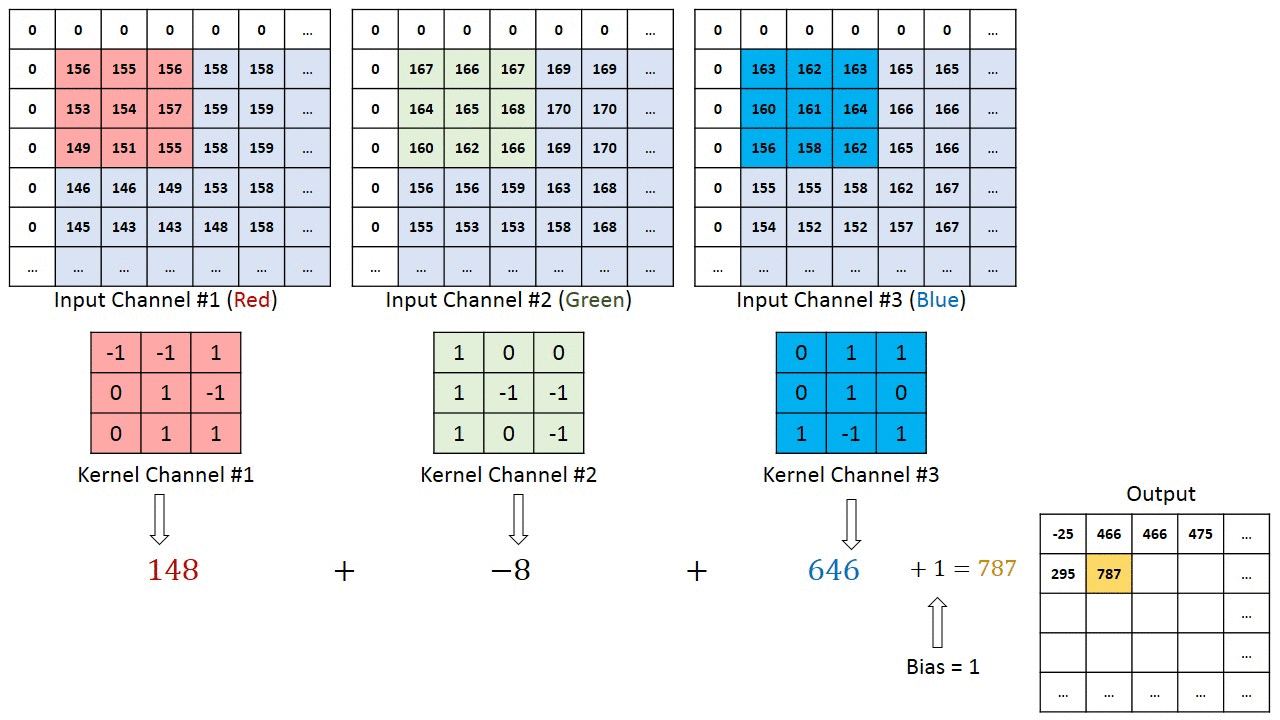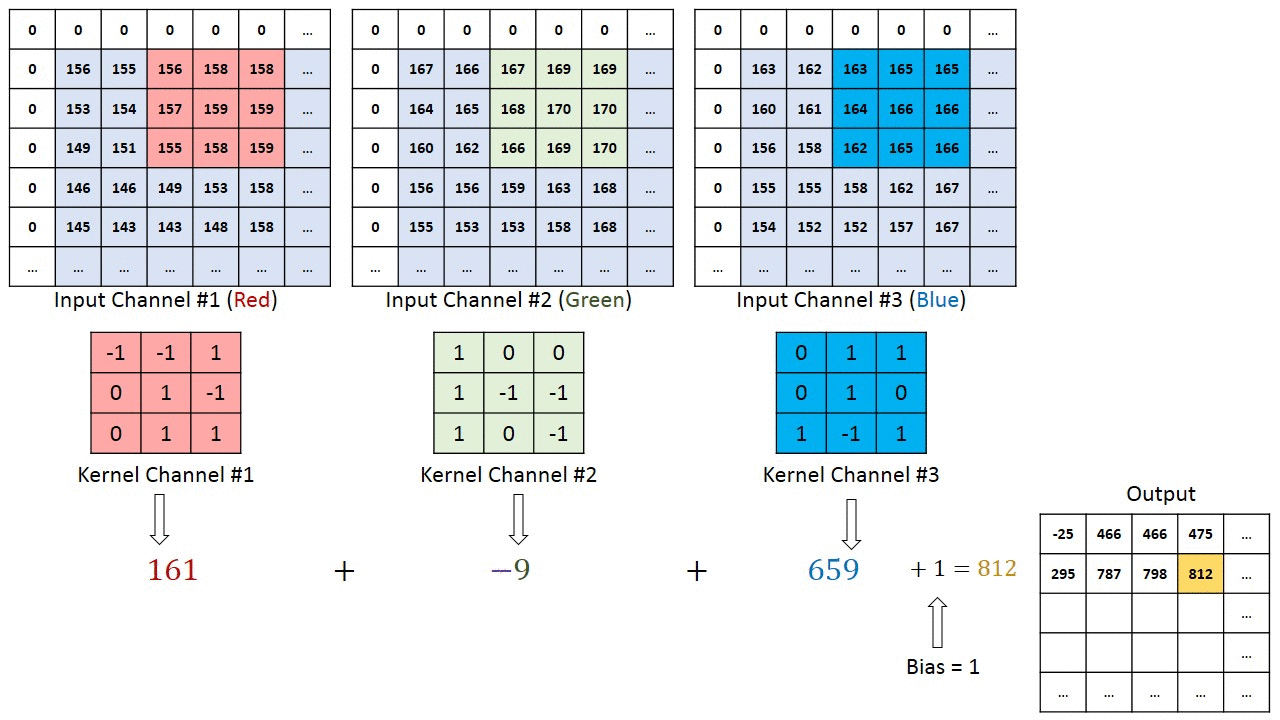 Операция свертки на матрице изображения MxNx3 с кернелом размерностью 3x3x3
Операция свертки на матрице изображения MxNx3 с кернелом размерностью 3x3x3
В случае, когда у изображения несколько каналов (например, RGB), кернел имеет ту же глубину, что и входное изображение. Матричное умножение выполняется между стэками Kn и In ([K1, I1]; [K2, I2]; [K3, I3]), и все результаты суммируются со смещением, чтобы выдать нам сжатый выходной сигнал одной глубины.
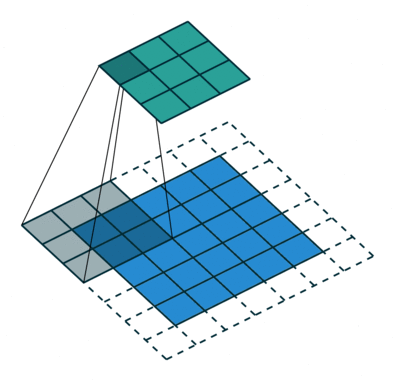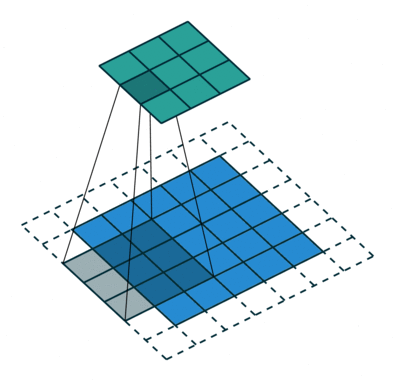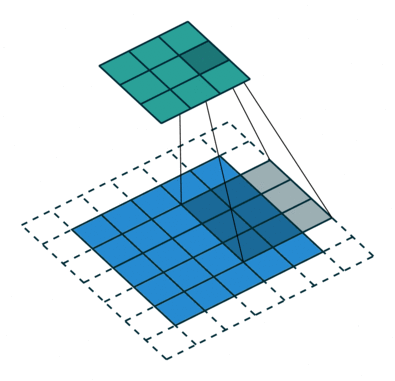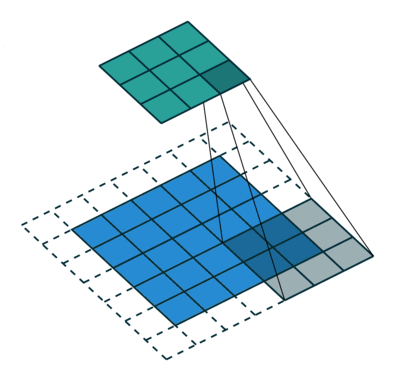 Операция свертки с длиной страйда = 2
Операция свертки с длиной страйда = 2
Цель операции свертки — извлечь из входного изображения высокоуровневые признаки, например, линии, края. ConvNets вовсе не обязательно должны быть ограничены только одним сверточным слоем. Традиционно, первый ConvLayer отвечает за захват низкоуровневых признаков, таких как края, цвет, градиентная ориентация и т.д. Благодаря добавленным слоям архитектура адаптируется также к высокоуровневым признакам, выдавая нам сеть, которая имеет столь же здравое понимание изображений в наборе данных, что и мы.
Эта операция может давать два типа результатов: один, в котором свернутый признак имеет меньшую размерность по сравнению с входным, в другом же размерность либо увеличивается, либо остается неизменной. Это делается путем применения паддинга без дополнения (Valid Padding) в случае первого или паддинга с дополнением нулями (Same Padding) в случае последнего.
 Same-паддинг: изображение 5x5x1 дополняется (is padded) нулями, чтобы создать изображение 6x6x1
Same-паддинг: изображение 5x5x1 дополняется (is padded) нулями, чтобы создать изображение 6x6x1
Когда мы преобразуем изображение 5x5x1 в изображение 6x6x1, а затем применяем к нему кернел размерностью 3x3x1, мы обнаруживаем, что размер свернутой матрицы — 5x5x1. Отсюда и название — Same-паддинг.
В то же время если мы выполним ту же операцию без паддинга, мы получим матрицу, которая имеет размеры самого кернела (3x3x1) — Valid-паддинг.
В данном репозитории хранится множество таких GIF-файлов, которые помогут вам лучше понять, как взаимодействуют паддинг и длина страйда для достижения результатов, соответствующих нашим потребностям.
Пулинговый слой (Pooling Layer)
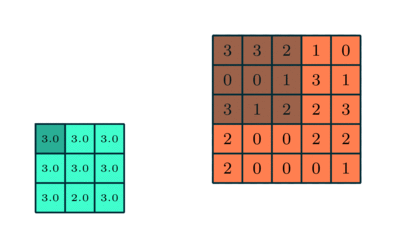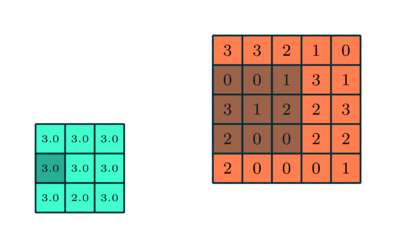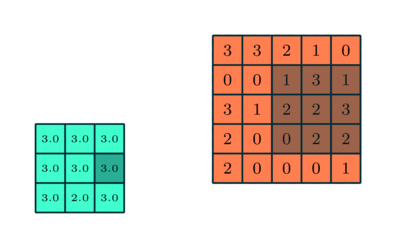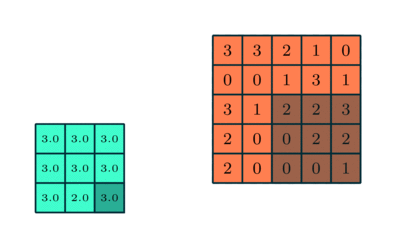 3x3 преобразуется с помощью пулинга в сложную функцию 5x5
3x3 преобразуется с помощью пулинга в сложную функцию 5x5
Подобно сверточному слою, пулинговый слой необходим для уменьшения размера свернутого элемента в пространстве. Это помогает уменьшить вычислительную мощность, необходимую для обработки данных, за счет уменьшения размерности. Кроме того, это важно и для извлечения доминирующих признаков, инвариантных вращения и позиционирования, таким образом поддерживая процесс эффективного обучения модели.
Существует два типа пулинга: максимальный (Max Pooling) и средний (Average Pooling). Максимальный пулинг возвращает максимальное значение из части изображения, покрываемой кернелом. А Средний пулинг возвращает среднее всех значений из части изображения, покрываемой кернелом.
Максимальный пулинг также выступает в роли шумоподавителя (Noise Suppressant). Он полностью исключает шумовые сигналы, а также совмещает подавление шума с уменьшением размерности. Средний же пулинг просто использует уменьшение размерности как способ подавления шума. То есть можно сказать, что Max Pooling работает намного лучше, чем Average Pooling.
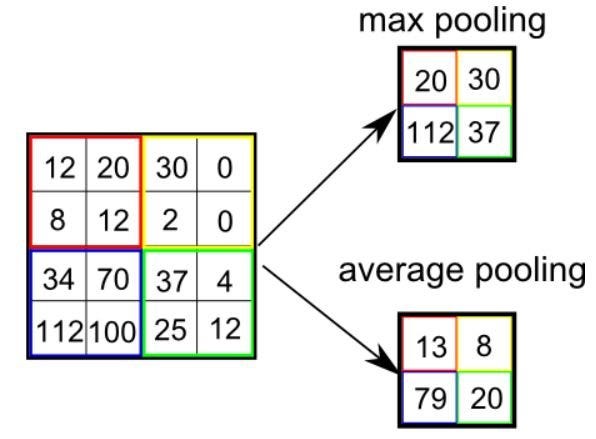 Типы пулинга
Типы пулинга
Сверточный слой и пулинговый слой вместе образуют i-й слой сверточной нейронной сети. В зависимости от сложности изображений количество таких слоев может быть увеличено с целью еще более точного захвата деталей низкого уровня, но ценой большей вычислительной мощности.
Выполнение описанного выше процесса позволяет модели успешно изучить признаки. Далее мы сглаживаем окончательный результат и передаем его в обычную нейронную сеть в целях классификации.
Классификация — Полностью Связанный Слой (Fully Connected Layer, FC Layer)

Добавление FC Layer — это (обычно) дешевый способ изучить нелинейные комбинации высокоуровневых признаков, представленных выходными данными сверточного слоя. FC Layer изучает возможную нелинейную функцию в этом пространстве.
Теперь, когда мы преобразовали наше входное изображение в подходящий формат для нашего многослойного персептрона, мы сведем изображение в вектор-столбец. Сглаженный вывод подается в нейронную сеть с прямой связью, и затем к каждой итерации обучения применяется обратное распространение. После серии эпох (epochs) модель способна различать доминирующие и некоторые низкоуровневые признаки изображений и классифицировать их с помощью техники Softmax.
Существуют множество архитектур доступных CNN, которые сыграли ключевую роль в построении алгоритмов, которые обеспечивают сейчас и будут обеспечивать работу Искусственного интеллекта как такового в ближайщем будущем. Некоторые из них перечисляю ниже:
- LeNet
- AlexNet
- VGGNet
- GoogLeNet
- RESNET
- ZFNet
GitHub Notebook — Распознавание рукописных цифр с использованием набора данных MNIST с TensorFlow






