Как собрать портфолио по Data Science? Часть I
Как найти работу в Data Science? Сложно получить работу, если просто знаешь статистику, машинное обучение, программирование и т.д. Недавно я обнаружил, что достаточно много людей обладает необходимыми для получения работы навыками, но у них нет портфолио. Иметь резюме важно, но обладание портфолио с публичным проявлением ваших навыков в Data Science может чудесным образом преобразить ваши шансы на трудоустройство. Даже при наличии рекомендации важно иметь возможность показать потенциальным работодателям насколько хорошо работаете, а не голословно заявить, что вы чем-то там занимаетесь. Этот пост содержит ссылки на ресурсы, где профессионалы Data Science (Data Science managers, data scientists, звезды соцсетей или те, кто занимает промежуточное между ними положение) и прочие обсуждают содержание портфолио и способы привлечь к себе внимание. Ну что ж, начнем!
Важность портфолио
Сбор портфолио важно, поскольку, помимо того, оно что улучшает ваши навыки, также помогает найти работу. Для большей ясности давайте договоримся, что под портфолио подразумевается публичные проявления ваших навыков в Data Science. Я позаимствовал это определение у Дэвида Робинсона, Chief Data Scientist из DataCamp, в его интервью с Мариссой Джемма в блоге Mode Analytics. На вопрос о том, как он получил свою первую работу в этой сфере, Дэвид сказал:
Для меня, самой эффективной стратегией была социальная активность. Под конец аспирантуры, я писал блог и работал над открытым кодом, так я получил публичные свидетельства моих навыков Data Science. Но то, как я получил работу в индустрии, было особенно поучительным примером полезности социальной активности. В аспирантуре я активно отвечал на вопросы на сайте по программированию Stack Overflow, и инженер из компании, в которую я позже устроился, наткнулся на один из моих ответов (я объяснял логику бета-распредления). Он был настолько впечатлен, что связался со мной [через твиттер] и, спустя несколько собеседований, меня взяли на работу.
Можно подумать, что так обычно в жизни не бывает. На самом деле часто бывает так, что чем активнее ты действуешь, тем чаще происходят подобные вещи. Из блога Дэвида:
Чем больше ты занимаешься общественной работой, тем выше шанс подобных поворотов судьбы: кто-нибудь видит твою работу и показывает тебе интересную вакансию, или тот, кто тебя собеседует, может быть наслышан о твоих проектах.
Часто забывают, что инженеры ПО и специалисты Data Science часто гуглят свои проблемы. Если твоя социальная активность помогает им решить эти проблемы, они будут о тебе хорошего мнения и постараются найти тебя.
Как обойти требования к опыту работы при помощи портфолио
Даже для стартовых позицией большинство компаний ищут кандидатов хоть с каким-нибудь опытом. Думаю, все знают шутку, что от студентов требуют 20-летний опыт программирования.

Проблема в том, что непонятно, как можно получить рабочий опыт, если нельзя получить работу не имея опыта. И если и есть ответ на этот вопрос, то это — проекты. Как сказал Уилл Стэнтон, проекты — это лучший заменитель рабочего опыта.
Если у тебя нет никакого опыта в Data Science, то тебе точно нужно участвовать в независимых проектах.
И вправду, когда Джонатан Нолис собеседует кандидатов, он ожидает услышать о последней решенной ими проблеме, или проекте, в котором они участвовали:
Я хочу услышать об одном из их недавних проектов. Я спрашиваю, как проект начался, как они поняли, что он стоит времени и сил, как они работали и чего добились. Кроме того, я спрашиваю, чему они научились во время проекта. Ответ говорит мне о многом: об их способности связно выражаться, почему проблема важна на глобальном уровне и как они справляются с напряженной работой.
Если у вас нет рабочего опыта в Data Science, лучше всего будет рассказать вашем участии в студенческом проекте в этой сфере.
Какие проекты включать в портфолио
Data Science настолько широкая сфера, что сложно предугадать, какого рода проекты работодатель ожидает увидеть. Уильям Чен, Data Science Manager из Quora, поделился своими мыслями на эту тему во время CareerCon 2018 в Kaggle (видео):
Мне нравятся проекты, в которых люди показывают, что их интерес к данным простирается дальше уровня домашних заданий. Любые курсовые работы, в которых вы разбирает интересный набор данных и приходите к интересным выводам… Хорошо поработайте над текстовой частью… Мне очень нравятся очень хорошие описания, в которых есть интересные и необычный результаты… Давайте визуальную информацию и делитесь своей работой.
Многие понимают значимость студенческих проектов, но еще они задаются вопросом, где взять интересный набор данных и что с ним делать. Джейсон Гудмэн, Data Scientist из Airbnb, написал пост Advice on Building Data Portfolio Projects, в котором он обсуждает различные идеи для проектов и дает хорошие советы о том, какие наборы данных следует использовать. Кроме того, он подтверждает идеи Уильяма по работе с интересными данными.
Я думаю, что для портфолио лучше подходят проекты, в которых меньше выпендрежного моделирования и больше работы с нетривиальными данными. Многие имеют дело с финансовой информацией или с данными Twitter, но такого рода данные не всегда интересны, так что эта работа проходит впустую.Кроме того, в статье он высказывает мысль, что web scraping — это отличный инструмент для сбора нетривиальных данных. Если вам интересно, как собрать свой набор данных при помощи web scraping на Python, посмотрите этот мой пост. Важно отметить, что, если вы из академической среды, ваша диссертация может считаться проектом (очень большим проектом). Можно послушать как Уильям Чен говорит об этом здесь.
Какие типы проектов НЕ надо включать в портфолио
Читая советы по составлению портфолио или резюме, я часто встречаю (настолько часто, что даже в этом блоге она встречается неоднократно) рекомендацию не включать стандартные проекты в свое портфолио.
Джереми Харрис в статье The 4 fastest ways not to get hired as a data scientist говорит
Сложно придумать более надежный способ отправить собственную резюме в папку “опредленно нет”, чем презентовать среди своих лучших работ банальный набор данных, который использовался только для проверки концепта.
Если у вас возникли сомнения, вот проекты, которые вам навредят больше, чем помогут:
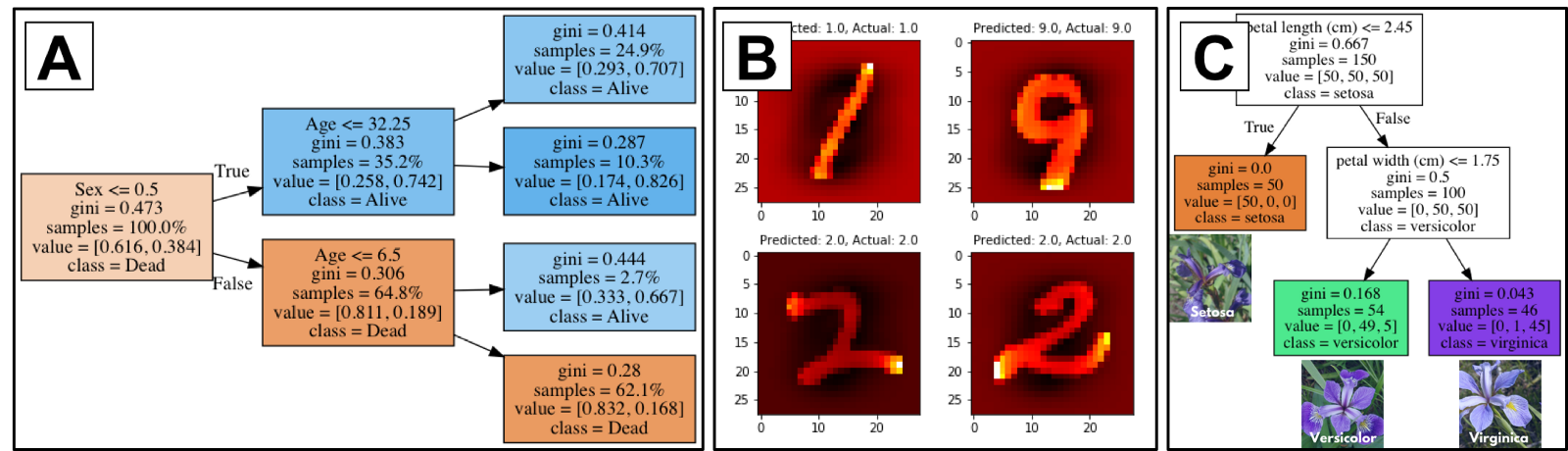
* Классификация выживших из данных по Титанику
* Классификация написанных от руки цифр из набора данных MNIST.
* Классификация видов цветов основанная на базе данных ирисов.
На приведенном ниже рисунке показаны частичные примеры классификации наборов данных Titanic (A), MNIST (B) и Ирисов (C). Существует не так много способов использовать эти наборы данных, чтобы отличать себя от других претендентов. Обязательно перечислите новые проекты.
Улучшение портфолио
Фавио Вазкез написал замечательную статью, в которой он рассказывает о том, как получил работу в Data Scientist. Естественно, одним из его советов было иметь портфолио:
Заведите портфолио. Если вы ищете хорошо оплачиваемую работу в Data Science, участвуйте в проектах с реальными данными. Если можно, выкладывайте их на GitHub. Кроме соревнование Kaggle, найдите что вам действительно нравится, или проблему, которую хотите решить, и используйте там свои знания.
Еще одним интересным замечанием была необходимость постоянно развиваться во время поиска работы.
У меня было почти 125 откликов на вакансиию Серьезно! Хотя, вы может и откликались на больше вакансий. У меня было что-то типа 25-30 ответов. Некоторые из них были просто “Спасибо, не надо”. И у меня было около 15 собеседований. И на каждом я научился чему-то. Я развивался. Мне много отказывали. К этому я готов не был. Но мне нравилось проходить собеседования (хотя и не все, если честно). Я много учился, писал код каждый день, читал много статей и постов. Они сильно помогли.
В то время как вы учитесь и развиваетесь, ваше портфолио тоже должно обновляться. Этот же подход можно найти и во многих других статьях с советами. Как сказал Джейсон Гудман:
Проект не заканчивается, когда вы его публикуете. Не бойтесь развивать и редактировать свой проект после того как он опубликован.
Этот совет особенно важен когда вы ищете работу. Есть много историй успешных людей вроде Келли Пенг, Data Scientist из Airbnb, которая проявляла настойчивость, и продолжала работать и развиваться. В одном из постов в своем блоге, она показала, сколько раз откликалась на вакансии и участвовала в собеседованиях:
Откликов: 475
Телефонных интервью: 50
Тестовые задания по data science: 9
Офф-лайн интервью: 8
Предложений: 2
Затраченное время: 6 месяцев
Видно, что она откликнулась на кучу вакансий и проявила настойчивость. В своей статье она даже упомянула, как именно нужно продолжать учиться на своем опыте собеседований:
Записывайте все вопросы на интервью, особенно те, на которые вы не смогли ответить. Вы можете опять провалиться, но уже провалитесь по другой причине. Всегда нужно продолжать учиться и развиваться.
Использование портфолио в кратком резюме
Вполне возможно, что потенциальный работодатель узнает о вашем портфолио из резюме, так что о нем тоже необходимо поговорить. В Data Science резюме необходимо сфокусироваться на своих технических навыках. Резюме — это шанс кратко рассказать о вашей квалификации и пригодности к той или иной роли. Рекрутеры и PR менеджеры очень бегло просматривают резюме, так что у вас есть мало времени на то, чтобы их впечатлить. Хорошее резюме повышает шанс на собеседование. Необходимо удостовериться, что каждая строчка и каждый раздел резюме несут важную информацию.,
Уильям Чен, Data Science Manager из Quora, написал статью “9 советов как создать резюме в Data Science”. Ниже приведено краткое изложение статьи. Обратите внимание, что проекты и портфолио упомянуты в пунктах 6, 7, 8 и, частично, 9.
- Длина: резюме должно быть простым и не больше одной страницы. Так оно лучше “зацепит” при беглом чтении. Лучше писать все в одну колонку: ее проще быстро пробежать глазами.

- Цель: Не упоминать. Цели не выделят вас среди других. Они крадут место у более важных вещей (навыки, проекты, опыт). Сопроводительное письмо (cover letter) совсем не обязательно, если вы только не сделаете его очень необычным.

- Курсы: Упоминайте только те подходящие курсы, которые как-то связано с вакансией.

- Навыки. Не расставляйте баллы своим навыкам. Если вы хотите дать оценку навыки, используйте слова. Например: уверенно пользуюсь, знаком. Можно и вовсе исключить оценки.

- Навыки: нужно перечислять те технические навыки, которые требует вакансия. Располагайте навыки по уровню владения ими.

- Проекты: не упоминайте распространенные учебные проекты и домашние задания. Они вас не смогут выделить среди других кандидатов. Упоминайте новаторские проекты.

- Проекты: показывайте результаты и ставьте ссылки. Если вы участвовали в соревновании Kaggle, проставьте свою перцентиль, чтобы читатель мог понять ваше место в соревновании. В секции Проекты всегда есть место для ссылок на описание проектов и статьи, чтобы HR менеджер или рекрутер смог углубиться в вашу работу (отсылочка к реальному миру, в котором приходится работать с путанными данными и учиться новому).

- Портфолио: заполните секцию с соцсетями. Начните в LinkedIn, это что-то типа продолжения резюме. Github и Kaggle могут показать вашу работу. Полностью заполните все анкеты и проставьте ссылки на другие ресурсы. Заполните описание для репозиториев GitHub. Заполните анкеты для блогов и прочих платформ, где вы делитесь знаниями (Medium, Quora). Смысл Data Science, собственно, в том, чтобы делиться знаниями и обсуждать отношение других к данным. Не стоит заполнять вообще все анкеты, хватит нескольких (мы это обсудим позднее).
- Опыт. Презентуйте свой опыт в соответствии с вакансией. Опыт — это ядро вашего резюме, но что же делать, если его нет? Заострите внимание на самостоятельных проектах: выпускных работах, исследованиях или соревнованиях Kaggle. Это заменит рабочий опыт, если у вас его нет. Не указывайте не относящийся к делу опыт.

Если вы хотите услышать как Data Science менеджеры разбирают портфолио и резюме, вот ссылка на Kaggle’s CareerCon 2018 (видео, обзор резюме).
Конец первой части. Вторая часть.
Оригинал статьи: towardsdatascience.com






