Что еще за Data Science?
Вот моя самая изощренная попытка: «Data Science - это дисциплина, позволяющая делать данные полезными». Все, теперь можете идти отсюда или отправиться на экскурсию по трем подразделам:
Термин, которому никто не дал определения
Если вы имели дело с ранней историей термина data science, вы увидите две темы, которые часто появляются вместе. Позвольте мне развлечь вас, перефразируя их:
- Большие данные "Big( ger ) data" означают много возни с компьютерами
- Статистики не смогут написать код, даже если от этого зависит их жизнь
И, таким образом, рождается наука о данных. Когда я впервые услышала определение этой вакансии, оно звучало следующим образом: «Data scientist — это статистик, который может кодить». Сейчас появится куча замечаний по этому поводу, но не лучше ли сначала посмотреть на data science?

Мне нравится, что в 2003 году Journal of Data Science в своем первом выпуске дал достаточно узкое определение: «Под Data Science мы понимаем почти все, что имеет отношение к данным». Эээ... все? Трудно подумать о чем-то, что не имеет ничего общего с информацией (я должна перестать думать об этом, иначе моя голова взорвется).
С тех пор мы видели множество мнений, от хорошо известной диаграммы Венна (ниже) до классического поста Мейсона и Виггинса.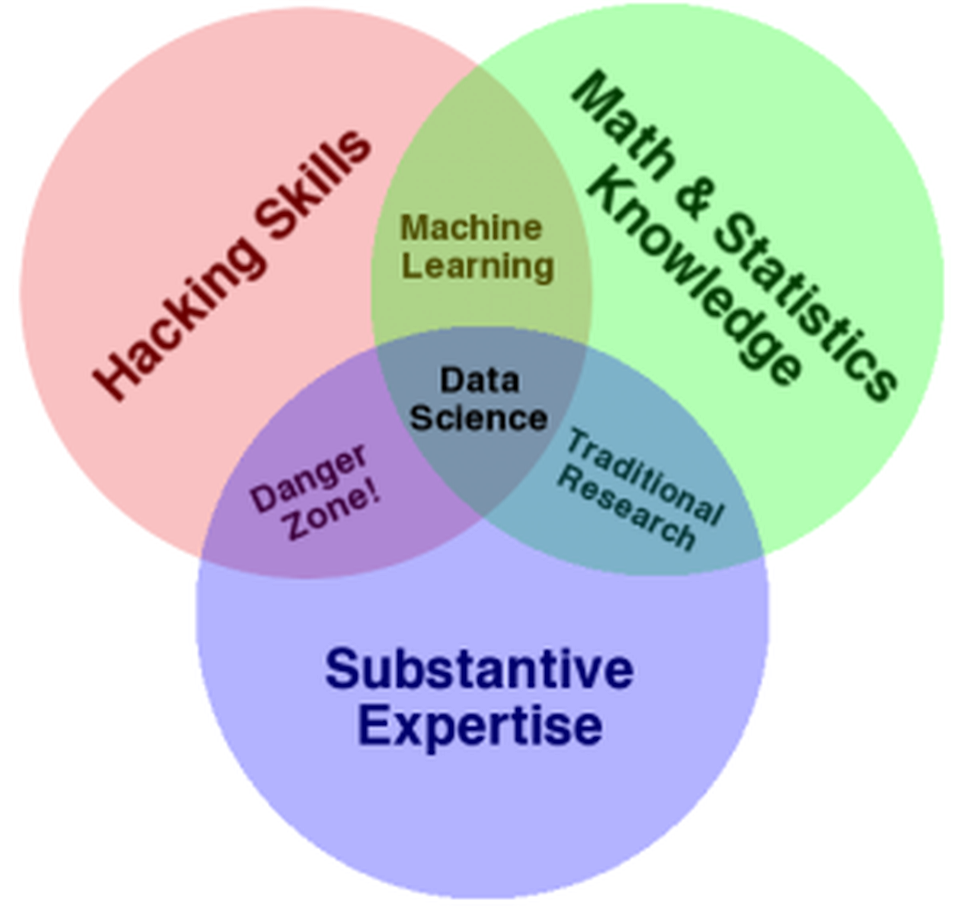
Определение науки о данных от Дрю Конвей. Моему личному вкусу больше подходит определение в Википедии.
В википедии есть определение, которое очень близко к тому, чему я учу своих учеников:
"Data Science представляет собой «концепцию, объединяющую статистику, анализ данных, машинное обучение и связанные с ними методы», с целью «понять и проанализировать фактические явления» при помощи данных."
Определение очень громоздкое, поэтому давайте посмотрим, смогу ли я сделать его поменьше и поприятнее:
«Наука о данных - это дисциплина, позволяющая сделать данные полезными».
Вы наверно сейчас думаете: «Хорошая попытка, Кэсси. Это мило, но это чудовищное упрощение. Как при помощи слова “полезно” можно описать все эти технические термины?»
Хорошо, хорошо, позвольте убедить вас картинками.

Вот вам схема науки о данных, совершенно верная определению Википедии.
Что это за штуки и откуда знать, в каком месте схемы мы располагаемся?
Если вы пытаетесь разобраться при помощи стандартных инструментов, притормозите. Разница между статистиком и инженером машинного обучения заключается не в том, что один использует R, а другой использует Python. Сравнение SQL vs R vs Python не рекомендуется по многим причинам, и не в последнюю очередь из-за того, что программное обеспечение развивается (в последнее время вы даже можете заниматься машинным обучением в SQL).
Обычно, когда новички решают разбить пространство, они всегда выбирают свой любимый способ — самый худший. Да, вы догадались: при помощи алгоритма (сюрприз! Этому их учат в университете). Умоляю, не выстраивайте систематизацию на противопоставлении гистограмм, t-тестов и нейронных сетей. Честно говоря, если вы умны, и у вас есть причина этим заниматься, вы можете использовать тот же алгоритм для любой части науки о данных. Может получиться монстр Франкенштейна, но я уверяю вас, что он результат в конечном итоге вы получите.
Хватит нагнетать! Вот классификация, которую я предлагаю:

Ничего-один-много
Это еще что такое? Конечно же, это решения! (При неполных данных. Когда вам понадобятся все необходимые вам факты, вы можете использовать описательную аналитику для принятия как можно большего количества решений. Посмотрите на факты, и все готово).
Именно наши действия и наши решения влияют на окружающий нас мир.
Я обещала, что мы поговорим о том, как сделать данные полезными. Для меня идея полезности тесно связана с действиями, влияющими на реальный мир. Если я верю в Санта-Клауса, это не имеет особого значения, если это не повлияет на мое поведение каким-то образом. Тогда, в зависимости от потенциальных последствий данного поведения, это может иметь большое значение. Благодаря нашим действиям и нашим решениям мы воздействуем на окружающий нас мир (и стимулируем его повлиять на нас).
Итак, вот вам новая практически применимая картинка, снабженная тремя основными способами сделать ваши данные полезными.

Data-mining
Если вы не знаете, какие решения вы хотите сделать, лучшее, что вы можете сделать, это пойти туда в поисках вдохновения. Это можно назвать интеллектуальным анализом данных, или аналитикой, или описательной аналитикой, или поисковым анализом данных (EDA, exploratory data analysis), или открытием знаний (KD, knowledge discovery), в зависимости от того, с кем вы тусовались в свои нежные годы.
Золотое правило аналитики: делайте выводы только о том, что вы можете видеть.
Если вы не знаете, как вы будете создавать свои решения, начинайте с этого. Отличная новость заключается в том, что это легко. Подумайте о своем наборе данных как о кучке негативов, которые вы нашли в темной комнате. Data-mining — это работа с оборудованием, вы как можно быстрее стараетесь проявить все изображения, чтобы вы увидеть удавшиеся снимки. Как и в случае с фотографиями, не относитесь слишком серьезно к тому, что вы видите. Не вы делали фотографии, поэтому не знаете, что осталось за кадром. Золотое правило data-mining: придерживайтесь того, что есть в наличии. Делайте только выводы о том, что вы можете видеть, и никогда — о том, что вы не видите (для этого вам нужны статистические данные и больше опыта).
Кроме этого, вы вряд ли можете кому-то навредить. Скорость решает, поэтому принимайтесь за практику.
Мастерство в data mining оценивается по скорости, с которой вы можете проверить свои данные. Так сложнее проспать интересные важные находки.
Темная проявочная комната может поначалу пугать, но это не надолго. Просто научитесь работать с оборудованием. Вот учебник R, и вот — Python для затравки. Как только процесс пройдет, вы можете назвать себя data analyst, и вы можете назвать себя экспертом аналитиком, когда сможете мгновенно проявлять фотографии (и все другие типы данных).
Статистические выводы
Вдохновение дешево, а тщательность стоит дорого. Если вы хотите перескочить за пределы данных, вам понадобится специальная подготовка. Так как я окончила и бакалаврита, и магиструтуру по статистике, я могу быть здесь немного предвзятой, но, на мой взгляд, статистический вывод (краткая статистика) является наиболее сложным и теоретически сложной из трех областей. Достичь в ней высот знаимает больше всего времени.
Вдохновение дешево, а тщательность стоит дорого.
Если вы намерены принимать высококачественные, проверенные и важные решения, основанные на выводах о мире за пределами доступных вам данных, вашей команде понадобятся статистические навыки. Отличным примером является тот момент, когда ваш палец нависает над кнопкой запуска для системы искусственного интеллекта, и вам приходит в голову, что вам нужно проверить его, прежде чем выпустить (всегда полезно, я серьезно). Отойдите от кнопки и позвоните статистику.
Статистика — это наука об изменении ваших решений (при условии неопределенности).
Если вы хотите узнать больше, я написала это 8-минутное изложение основ статистики специально чтобы вас порадовать.
Машинное обучение
Машинное обучение по существу создает рецепты для маркировки предметов с использованием примеров вместо инструкций. Я написала несколько сообщений об этом, в том числе о том, отличается ли он от ИИ, как начать работать с ним, почему у компаний не всегда получается с ним работать, и первые две статьи в серии, которая простым языком разбирает все технические тонкости (начало здесь). О, и если вы хотите поделиться ими с друзьями, не говорящими по-английски, вот здесь есть куча переводов.

Data engineering
Как насчет data engineering, работы, которая прежде всего доставляет данные для команды data science? Поскольку это сложная область сама по себе, я стремлюсь защитить ее от захватнических устремлений data science. Кроме того, у них больше биологического сходства с разработкой программного обеспечения, чем со статистикой.
Разница между data engineering и data science — это разница до и после.
Коль вам угодно, можете представлять разницу между data engineering и data science, как разницу между тем, что было до, и тем, что было после. Большая часть технической работы, связанной с порождением данных (до), может быть удобно названа data engineering, и все, что мы делаем, после того, как данные появились (после) — data science.
Decision intelligence
Decision intelligence (DI) - это все, что относится к принятию решений в том числе когда решения масштабируются по данным. Поэтому DI является инженерной дисциплиной. DI дополняет прикладные аспекты науки о данных идеями социальных и управленческих наук.
Decision intelligence добавляет компоненты из социальных и управленческих наук.
Другими словами, это надмножество тех элементов науки о данных, которые не занимаются научными вещами, такими как создание фундаментальных методологий для общего использования.
Хотите добавки? Вот разбивка ролей в data science проекте. Развлекайтесь пока я пойду постучу по клавиатуре.
Оригинал статьи: hackernoon.com






